Mit6.S081:lab Multithread
实验开始之前需要将git分支切换到thread分支不然有些文件你是没有的
1 | $ git fetch |
Uthread: switching between threads (moderate)
简介
本次实验是要实现用户级的线程上下文切换机制。在实验中提供了两个文件user/uthread.c和user/uthread_switch.S,在uthread.c文件中提供了一些用户级线程要使用的包,还有三个线程的代码,在这个文件中缺少了创建线程与切换上下文的代码。
任务:创建线程和保存/恢复寄存器以在线程之间切换的计划,并实现该计划。当你完成后,评分应该表明你的解决方案通过了线程测试。
当完成之后可以运行uthread,输出的结果如下所示:
1 | $ make qemu |
但是如果没有实现线程切换代码,程序是不会有任何的输出。因此我们需要在实验中添加,代码到thread_create() 、 thread_schedule()两个函数的指定区域,再添加汇编代码到thread_switch.S。
thread_switch.S保存的是切换上下文的汇编代码,在kernel/switch.S中便有所实现,就是保存/恢复callee寄存器的值,因为callee寄存器在函数调用中不会被保存。thread_schedule()函数与内核文件proc.c/scheduler()函数的实现原理是相同的,就是找到一个RUNNALBE线程并调用thread_switch切换上下文,但是uthread中并没有实现上下文切换。thread_create()函数就是创建一个线程,在内核代码proc.c/allocproc函数中就有创建当前线程的上下文的代码。
如下面代码所示,我们将上下文的ra寄存器保存为了forkret的地址,那么当scheduler切换到该线程后就会转到forkret函数,并且返回用户空间。后面讲栈指针设置为了栈的地址设置为了内核栈的上一页,值得注意的是栈是从上往下增长的。
1 | static struct proc* |
HINTS:一些关于调试的用户文件的技巧,如果感兴趣的话可以自行查看
实现
用户级线程切换与内核级线程切换并没有什么区别,所以大部分的代码都可以cv内核的代码。
context:上下文结构
context直接cv内核文件中的contex结构体(kernel/pro.h)就可以了,然后添加context字段到thread结构体中。
1 | ----uthread.c |
上下文切换
上下文切换代码也可以直接cv内核上下文切换的汇编代码(kernel/switch.S),如下所示我们将代码粘贴到uthread_switch中。
1 | .text |
创建线程:
与allocproc一样,在创建线程时候需要分配线程上下文的sp与ra寄存器,func就是每个线程的要执行的函数,在上下文切换后就是返回到func函数中。
1 | void |
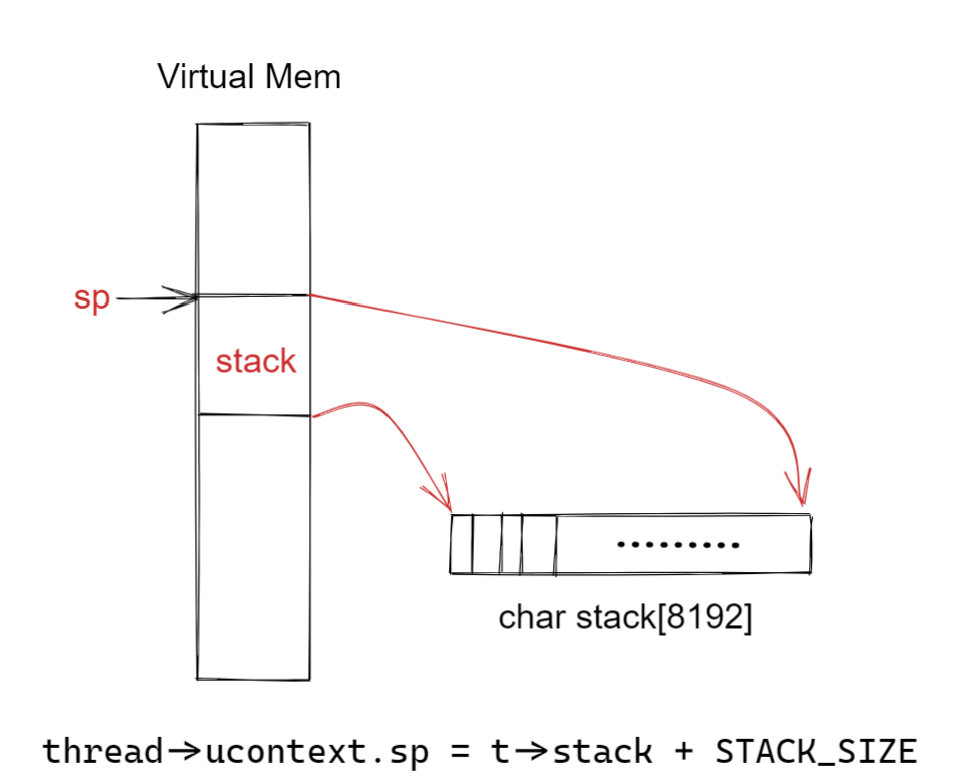
在thread结构体中有一个char stack[STACK_SIZE]字段,那么也就是说线程的栈空间是两个页,8192字节。那么t->stack就是栈的底部,由于risc-v的栈是从上往下增长的,所以我们要将栈指针设置为stack数组的最后一个值即可,布局如下图所示。
线程调度
线程调度函数没什么特别的,我们需要做的就是调用thread_switch上下文切换的函数。
1 | void |
Using threads (moderate)
简介
写在前面:这个实验与后一个实验本身都不难,因此实验文档只是通过翻译软件翻译的,建议看官方原文档。
在本实验中,您将探索使用哈希表进行线程和锁的并行编程。这个实验的过程使用的是UNIX的pthread线程库,因此不需要在qemu或是xv6上运行,在正常的linux上运行即可。您可以通过man pthreads从手册页找到有关它的信息,也可以在在网络上搜索上查找。
文件notxv6/ph.c包含一个简单的哈希表,如果从单个线程使用它是正确的,但如果从多个线程使用它就不正确了。在xv6目录中,输入如下:
1 | make ph |
请注意,要构建ph, Makefile使用的是操作系统的gcc,而不是6.S081工具。ph的参数指定在哈希表上执行put和get操作的线程数。运行一段时间后,./ph 1将产生类似于以下的输出:
1 | 100000 puts, 3.991 seconds, 25056 puts/second |
您看到的数字可能与这个示例输出相差两倍或更多,这取决于您的计算机有多快,是否有多个核心,以及它是否忙于做其他事情。
ph运行两个基准。首先,它通过调用put()将许多键添加到哈希表中,并以每秒放置次数为单位打印实现的速率。它使用get()从哈希表中获取键。它打印由于put操作而应该在哈希表中但缺少的数字键(在本例中为零),并打印每秒实现的get次数。
通过给ph一个大于1的参数,可以告诉它同时从多个线程使用它的哈希表。试试ph 2:
1 | ./ph 2 |
这个./ph 2输出的第一行表明,当两个线程并发地向哈希表中添加条目时,它们达到了每秒53,044次插入的总速率。这大约是运行ph 1时单线程速率的两倍。这是一个出色的“并行加速”,大约是2倍,这是人们可能希望的(即两倍的内核产生两倍的单位时间的工作)。
但是,缺少16579个键的两行表明,大量本应在哈希表中的键不在哈希表中。也就是说,put应该将这些键添加到哈希表中,但是出了问题。看看notxv6/ph.c,特别是put()和insert()。
为什么有2个线程,而不是1个线程丢失的键?用两个线程确定可能导致丢失密钥的事件序列。
为了避免这种事件序列,请在
notxv6/ph.c中的put和get中插入lock和unlock语句,以便在两个线程中丢失的键数始终为0。相关的pthread调用是:c
2
3
4
pthread_mutex_init(&lock, NULL); // initialize the lock
pthread_mutex_lock(&lock); // acquire lock
pthread_mutex_unlock(&lock); // release lock当
make grade说你的代码通过了ph_safe测试时,你就完成了,这需要两个线程的零丢失键。此时,ph_fast测试失败也没关系。
不要忘记调用pthread_mutex_init()。先用一个线程测试你的代码,然后用两个线程测试。它是否正确(即你是否消除了丢失的键?)?相对于单线程版本,双线程版本是否实现了并行加速(即每单位时间内完成的总工作量更多)?
在某些情况下,并发put()操作在哈希表中读取或写入的内存没有重叠,因此不需要锁来相互保护。您可以更改ph.c以利用这种情况来获得一些put()s的并行加速吗?提示:每个哈希桶加一个锁怎么样?
不要忘记调用pthread_mutex_init()。先用一个线程测试你的代码,然后用两个线程测试。它是否正确(即你是否消除了丢失的键?)?相对于单线程版本,双线程版本是否实现了并行加速(即每单位时间内完成的总工作量更多)?
在某些情况下,并发put()操作在哈希表中读取或写入的内存没有重叠,因此不需要锁来相互保护。您可以更改ph.c以利用这种情况来获得一些put()s的并行加速吗?提示:每个哈希桶加一个锁怎么样?
实现
- 首先声明了一个全局变量lock,在main函数中对这个锁变量进行初始化。
- 这里我使用了两个宏定义了加锁与解锁的两个函数(图的方便而已)
对于ph程序并不需要增加多少代码,问题处是在使用put函数时并发修改哈希表的键值时候,会出现更新丢失(如:当两个线程同时找到同一个空闲的entry,并同时调用insert,那么第一个完成insert调用的,会被第二个覆盖)等等问题,因此我们需要在put过程增加锁,将put操作视为原子操作就可以了。
1 | static pthread_mutex_t lock; |
为什么get过程不需要加锁呢?
首先get是幂等操作(这个操作不会对共享数据产生影响,简单来说就是读操作),其次在实验中没有序列化与一致性的要求,简单来说就是实验中没有读操作与写操作交错,并检测读取数据的值是否正确,这些都是分布式系统的内容,也就不过多延申了。
省去了锁的开销,也可以满足文档中对ph程序并发速率的提升要求。
减少锁竞争
在实验文档最后,有一提问是否可以给每一个哈希桶添加一个锁提高并发速率,这个显然是可以的,但是只针对的是哈希桶比较多的情况下.在并发写入要求高并且哈希桶少时反而速率更慢,主要是锁使用的开销。在实验8 locks中的两个实验会涉及到锁竞争问题。
1 | pthread_mutex_t lock[NBUCKET]; |
Barrier(moderate)
简介
在本实验中,您将实现一个barrier:应用程序中的一个点,所有参与的线程必须等待,直到所有其他参与的线程也到达该点。您将使用pthread条件变量,这是一种序列协调技术,类似于xv6的睡眠和唤醒。
文件notxv6/barrier.c包含一个错误的barrier。
1 | make barrier |
./barrer 2,其中2这个参数是指定在barrier上同步的线程数(barrier.c.nthread)。每个线程执行一个循环。在每个循环迭代中,线程调用barrier(),然后休眠一个随机的微秒数。assert触发,因为一个线程在另一个线程到达barrier之前离开了barrier。期望的行为是,每个线程都阻塞在barrier()中,直到它们的所有n个线程都调用了barrier()。
本实验的任务:是实现期望的barrier原理。除了在ph赋值中看到的锁原语之外,还需要以下新的pthread原语;。
plaintext
2
pthread_cond_broadcast(&cond); // wake up every thread sleeping on cond确保你的解决方案可以通过barrier测试
pthread_cond_wait在被调用时释放互斥锁,并在返回之前重新获取互斥锁。我们已经给出了barrier_init()。你的工作是实现barrier(),这样恐慌就不会发生。我们已经为你们定义了结构barrier;它的字段供您使用。
有两个问题会使你的任务复杂化:
- 你必须处理一连串的barrier调用,每次调用barrier称为一轮。bstate.round记录当前轮。每轮所有线程都到达barrier,我们应该增加bstate。。
- 你必须处理这样一种情况:在其他线程退出barrier之前,一个线程在循环中竞争。特别是,从一轮到下一轮重用bstate.nthread变量,当上一轮仍在使用bstate.nthread变量时,确保离开barrier并在循环中竞争的线程不会增加这个变量。
实现
这个实验就是完成barrier函数,在主函数中就是创建多个线程并发调用barrier。多个线程全部调用完一次barrier后,就增加bstate.round变量。
那么该如何控制当全部线程都完成一次调用后,再递增round变量呢?这时候就需要使用到线程的条件变量了(go语言的channel与条件变量与其相似),其原理就是xv6中的睡眠锁。
这时候实现就是,当一个线程以及运行完一次barrier后就将休眠,只有当最后一个调用完barrier的线程将round+1再将其他线程唤醒,继续往下运行即可.
1 | static void |
这时候我们再运行barrier程序,会出现一个问题就是nthread没有被重置,如下我们再barrier最后增加一行代码编译代码再运行,仍然还是会有问题,这样的更新在并发时会有所问题,多次重置bstate.nthread变量。
例如:当两个线程a、b,a满足条件唤醒b,这时候b还没有被唤醒(没有加锁),这时候a直接将bstate.nthread赋值为0,进入下一轮并且进入下一轮的休眠状态。这时候b被唤醒,又将bstate.nthread赋值为0,这时候进入下一轮也会休眠,这就是死锁了。
1 | static void |
正确的修改方法是,就是只重置一次bstate.nthread的变量,那么就是在下一轮通过判断bstate变量进行修改即可。
1 | static void |
总结
由于我在此之前已经做过了mit6.824的实验对于并发编程又所了解所有解决这个实验也比较简单,这个实验比较有意思的部分就是实现用户级的线程切换程序,大致也对于pthread的调度方式有了深刻的了解。