xv6:文件系统
File system
写在前面:本文是基于xv6以及MIT6.S081课程内容所写的笔记,在阅读时配合xv6源码理解效果更佳。
简介
设计文件系统的主要目的是为了组织与存储数据。文件系统中提供了共享用户与程序的数据的方式。同时也提供了持久化(persistence),也就是在设备丢失并重启后,数据仍然能够保存,众所周知内存(RAM)设备的数据断电后是会丢失的。
xv6的文件系统提供了UNIX风格的文件、目录、路径名和在磁盘存储数据(persistence)的方式。同时这样的文件系统也会给设计带来一些挑战:
- 保存在硬盘上(on-disk)的数据结构:文件系统需要表示目录和文件名称的树(tree),记录每个文件内容块的标识,并记录磁盘中那些块是空闲的。
- crash恢复(crash recovery):如果电脑crash发生,文件系统需要在重启后正常工作。问题在于在crash会中断更新的顺序,并且导致on-disk数据结构与文件数据不一致。
- 维持不变量(maintian in variant):不同的进程同时操作一个文件的时候,需要协调数据的更新,预防并发读写的数据竞争。
- 内存缓存常用块(in-memory cache of popular blocks):磁盘的访问通常会比内存访问慢几个数量级,所以文件系统需要维持常用数据块在内存中的缓存。
xv6中文件系统的设计是比较简单的,但是用于学习是十分不错的。
xv6文件系统
xv6文件系统的实现被组织为7个层,如下图所述:
- disk layer,进程在磁盘设备上读写块(blocks);
- buffer cache layer,将磁盘的块缓存在内存中并同步访问,并且在只有一个内核进程才能在一个时间段内修改缓存,将该块存入对应磁盘的块中
- logging layer,将更高的层中对于几个或是多个的数据块的更新保存在一个事务中(transaction),并且却表这些块能够在面临crash时能够原子的更新(要么全部更新,要么都不更新)。
- inode layer,提供单独的文件的信息(metadata),每一个文件都有唯一编号(i-number)的
inode,一个文件只有一个inode的,在磁盘中有固定的块会保存inode数据。 - directory layer,将目录设置为了一种特殊的inode种类,也就是说目录是文件,目录会保存目录或文件的条目的序列,每一个条目都会包含文件名与i-number。
- pathname layer,提供分层级的路径命名方式,如/usr/rt,/xv6/fs.c,解析路径明时使用递归的方式查询(find实验中就有所涉及)。
- descriptor layer,将Unix资源(pipes,devices、file…)抽象化,使用文件系统的接口,简化操作磁盘文件的方式。

以上便是文件系统与xv6文件系统大致设计,接下来将会由底层的disk layer逐渐讲解到顶层的descriptor layer。
Disk Layer
磁盘硬件交互
从最低层Disk layer讲起,在实际中risc-v主板上会连接许多的存储设备,有SSD与HDD两种常用的磁盘类型,两者的区别在于性能与成本方面。
这些存储设备连接到了电脑总线(bus)之上,总线也连接了CPU和内存。一个文件系统运行在CPU上,将内部的数据存储在内存,同时也会以读写block的形式存储在SSD或HDD。读写文件的接口比较简单有read/write,然后以block编号作为参数。
在下图中是CSAPP中硬件的组织,通常情况CPU读取磁盘的文件或是程序,都会将其加载到内存中。

术语:sector与block
- sector,通常是磁盘驱动可以读写的最小单元,它过去通常是512字节。
- block,通常是操作系统或者文件系统视角的数据。它由文件系统定义,在xv6中定义为1024字节。所以xv6中
block = 2 * sector。通常来说一个block对应了一个或者多个sector。
但是这两个术语没有明确的界限,所以容易导致混淆。
磁盘布局
从文件系统的角度来看磁盘还是很直观的。因为对于磁盘就是读写block或者sector,我们可以将磁盘看作是一个巨大的block的数组,数组从0开始,一直增长到磁盘的最后。
磁盘块与类型
- boot block,block0,被用作boot sector来启动操作系统。操作系统也是一个程序保存在数据块中,点击开机后,boot loader会将该操作系统加载内存中。xv6中没有使用boot block。
- super block,block1通常被称为super block,它描述了文件系统的线管信息。包含磁盘上有多少个block共同构成了文件系统这样的信息。通过block1构造出大部分的文件系统信息。
- log block,block2-block31。实际上log的大小可能不同,这里在super block中会定义log就是30个block。
- inode block,在block32到block45之间。一个inode是64字节,描述的了文件的一些相关信息。
- bitmap block,构建文件系统的默认方法,它只占据一个block。它记录了data block是否空闲。一个字节有8个位,那么一个字节可以表示8个数据块(通过指定位0和1表示数据块是否被使用),例如
0000 0110就可以表示第2和第3个数据块被使用了,一个bitmap就可以表示8*1024个数据块。 - data block,block46以后的块都属data block,data block存储了文件的内容和目录的内容。

通常来说,bitmap block,inode blocks和log blocks被统称为metadata block。它们虽然不存储实际的数据,但是它们存储了能帮助文件系统完成工作的元数据。
代码:超级块结构体
这个结构体描述了文件系统中一些基本信息,如文件系统block、inode、log的数量等信息。
1 | struct superblock { |
代码:超级块初始化
文件和目录内容都保存在磁盘块中,这就需要一个空闲池(free pool)用于分配空闲块。xv6块分配器(block allocator)维持了一个bitmap块,一个位(bit)代表一个块,0代表块空闲、1代表块正在使用。mkfs(mkfs/mkfs.c,用C语言编写的程序,本质上时制作一个镜像也就是一个文件)程序设置了这些位对应了各个块的编号,有boot block、superblock等。
输入make clean后再输入make qemu,可以从makefile输出信息看到如下消息所示,第一条是makefile的编译信息,大概就是将 REAMDE、user/_cat,这些程序加载到磁盘,实际是将这些程序写入到了fs.img文件中,最后将这个镜像文件加载到qemu的虚拟磁盘上。
1 | mkfs/mkfs fs.img README user/_cat user/_echo user/_forktest user/_grep user/_init user/_kill user/_ln user/_ls user/_mkdir user/_rm user/_sh user/_stressfs user/_usertests user/_grind user/_wc user/_zombie user/_bigfile |
接下来的makefile的输出信息便是mkfs文件系统的printf语句的输出信息,大致就是告诉你文件系统中块的布局及分配情况
1 | nmeta 70 (boot, super, log blocks 30 inode blocks 13, bitmap blocks 25) blocks 199930 total 200000 |
在后面有一个balloc开头的输出语句,这实际上是块分配器的函数,接着了解一下块分配的相关操作。
在mkfs/mkfs.c中就就编写了超级块的初始化数据,主要是定义了文件系统的大小、磁盘块的数量、日志块的数量、日志块的开始编号、inode块的开始编号、bmap块的开始编号,如下:
1 | .... |
Buffer cache layer
简介
buffer cache层主要完成以下两个任务:
- 同步对磁盘块的访问:只有一个磁盘块的一个副本保存在内存中,并且只有一个内核线程能够在同一时间内操作这个内存副本。
- 缓存常用的块以提升性能:访问磁盘是特别慢的操作,缓存经常使用的块在内存中,可以加快数据访问的速度。
在bio.c文件中声明了buffer cache层提供的三个接口:buffer cache层对每一个buffer包含一个sleeplock,保证buffer的同步性。
- bread:获取一个buf,其中包含指定磁盘块的副本,这个副本能够在后续在磁盘中被读取与修改。返回一个已锁定的buf。
- bwrite:将已修改的buffer写回对应的磁盘块中。
- brelse:内核线程完成buffer相关修改后,调用该接口释放这个buf。释放锁定的buf。
buffer cache是内存中保存的固定长度的双向buf(结构体)链表,那么也就是说内存中不可能缓存所有的磁盘块,那么当buffer cache满了之后,读取一个新的磁盘块,就需要回收buf节点。在xv6中使用了LRU(least recently used)算法,也就是将最少使用的块写回磁盘回收buf节点。
代码
buf结构体
- valid:buf中是否含有块的副本。
- disk:buffer块的内容是否已经写回了磁盘,这将会改变块的内容。
- dev:设备id。
- blockno:磁盘块的编号。
- refcnt:引用计数,持有buf节点
sleeplock的数量。
1 | struct buf { |
1 | struct { |
buffer cache初始化:
创建双向链表bcache,bcache中有30个buf节点。如下图
- 由右到左是使用
next指针,这个是MRU(most recently used)链表。右边的第一个就是最常(popular)用的buffer节点,依次使用next指向读取下一个块,这些块的常用程度依次下降。 - 从左到右是使用
prev指针,这则是LRU链表,与MRU链表刚好相反。在xv6中会将LRU链表的节点的buffer写回磁盘。
下图中bcache.head作用是使用prev与next指针指向MRU与LRU两个方向的链表的头节点。

下述代码中,将每一个buffer节点都设置了一个sleeplock,遍历bcache.buf的所有节点创建了双向链表。
1 | void |
bread:获得指定块的buf,返回以锁定的buf
在bread接口中会调用bget函数,返回指定磁盘块号的buf。如果该buf是新分配的节点里面没有数据,则调用virtio_disk_rw接口读取磁盘块的内容到buf中。
1 | struct buf* |
bwrite:将buffer写入磁盘块
一旦bread读取了磁盘并将buffer返回了调用者,调用者将独占使用这个buffer。只有在调用了bwrite之后将修改的数据写入磁盘才能释放buffer。
1 | void |
bget:获取指定块的buffer
bget中会做两件事:
- 查找已缓存的buf:使用next指针扫描MRU链表,通过判断
dev与blockno参数,如果已经缓存了这个块,获取sleeplock后返回已锁定的buf节点。反之说明没有缓存指定的磁盘块,则进入下一步。 - 查找空buf:使用prev指针扫描LRU链表,查找没有使用过的buf节点(
b->refcnt = 0),将该buf节点的相应字段填入,获取sleeplock后返回已锁定的buf节点。
为了确保同步性,文件系统使用锁控制同步,因此每一个磁盘块只能缓存在一个buffer中,确定readers能够看见写入。bget函数中对链表扫描,检查buf节点是否缓存,这个过程持有bcache.lock直到返回,以确保不会多个buf节点缓存一个磁盘块或是一个buf节点缓存多个磁盘节点。
1 |
|
bget中在bcache.lock关键区(critical section)之外,使用sleeplock保护buf节点数据安全,保护对磁盘块的buf节点的读写。在关键区之内,主要是保护了b->refcnt变量保证buf节点不被重新用于其他磁盘节点,保护已缓存块的信息。
brelse:调用者释放buffer,减少引用计数
当调用者完成了buffer的操作,必须调用brelse(b-release)释放块。brelse释放sleeplock并减少引用计数。当引用计数为零(b->refcnt=0)的buf节点移动到链表的最右方(如下图所示),这个buffer节点就变成了最经常使用的节点了,在bget中查找已缓存的节点便可以最先找到该节点。
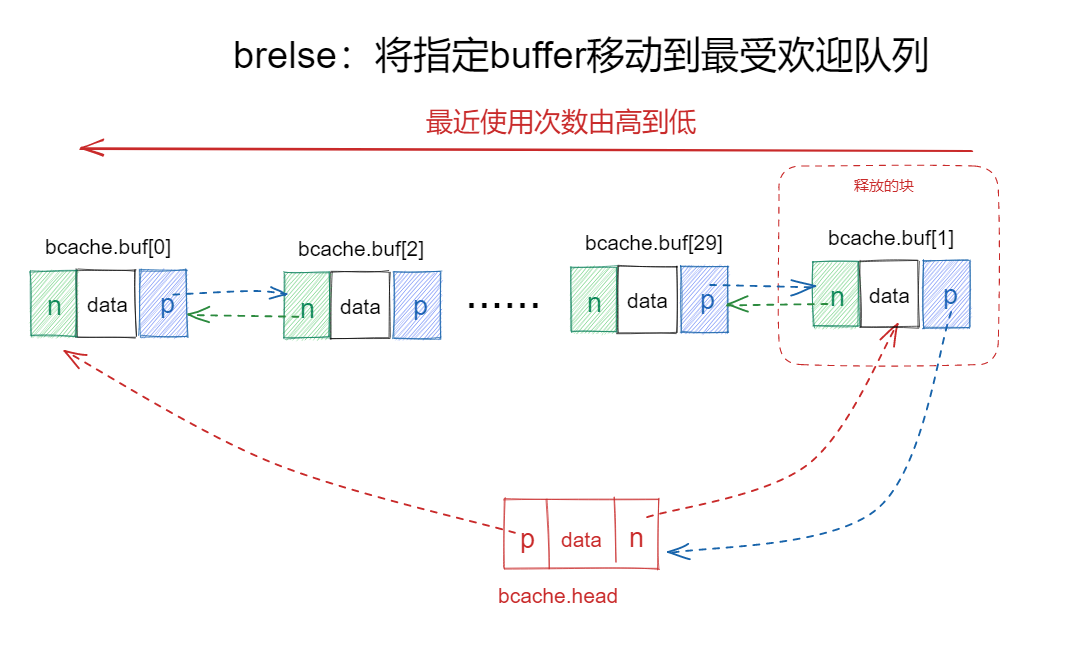
移动buf节点会引起buffer cache链表以最近使用频率进行排序:(从右往左)在链表的第一个buffer是最近最多使用的,最后一个则是最近最少使用。
1 | void |
Logging layer
问题
crash safty
在实际中:当使用make命令编译文件时候,会频繁的与文件系统交互,创建读写文件,但是在make命令执行的期间,你的笔记本断电了。那么到你重启笔记本后,使用ls命令显示文件会呈现你期望的状态。
crash恢复(crash recovery)是文件系统中最有趣的问题之一。这个问题主要是因为许多文件系统的操作会伴随着写磁盘操作,要写入磁盘的数据是保存在内存中的(已经在内存中修改数据),但是当数据写入磁盘到一半或是没有将内存的数据写入完,就会出现一个问题——重启系统后导致数据不一致。
crash情景
以创建和写入x文件为例,主要调用了open与write这两个系统调用。那么echo期间打印一些写入磁盘的关键操作,忽略了读取操作,如下所示:
1 | echo "hi" > x |
第一二句得知,分配inode块33,就是为x文件分配一个inode,并且初始化inode的数据,(将磁盘块读取到buffer cache,并内存中初始化后,写回磁盘)。接着是更新根目录的数据块,就是添加x文件的描述,如下图所示写到了46这个磁盘块上。最后再是更新系统根目录的inode,再是将x文件的inode写回磁盘(将buffer cache中的inode写回磁盘)。
那么此时在上图中crash1点出现系统crash,那么保存在buffer cache的内容将会被全部清空。那么系统就会丢失x文件的inode,但是这个inode已经被标记为已使用(可以查看ialloc的实现逻辑)。在根目录下也找不到x文件的inode,也就无法删除这个inode。这个问题也是可以恢复的,就是在重启时检查所有的inode块,如果inode没有数据块就直接删除这个inode就可以了,显然这是十分麻烦的方案。
一个还有风险情景是,同一个数据块属于两个文件,例如:在文件截断(将文件大小修改为0,释放文件内容)时发生crash,由于这些写磁盘操作是序列化的,那么就会导致inode中引用了一个数据块,但是在bitmap块中却标记了这个块为空闲。
inode引用了空闲块会造成的问题是,在重启后,内核可能分配这个数据块给其他文件,这就会造成两个不同的文件的内容指向了同一个数据块。如果xv6支持多用户,这就会造成安全问题,因为旧文件的用户能够读写新文件用户的数据。
简介
日志简介
为了恰当的应对文件系统的crash问题,因此在xv6中提供的解决方案的方案是日志(logging),这是来自与数据库的解决方案,提供了如下属性:
- 原子性(atomic),确保文件系统的系统调用是原子性的。这个属性和数据库事务的原子性是完全一样的,比如你调用
write系统调用,所有写入磁盘块的操作,要么全部成功,要么全部失败,不会出现写入部分的问题。 - 快速恢复(Fast Recovery),在重启之后,不需要做大量的工作来修复文件系统,只需要非常小的工作量。在另一个解决方案中,可能需要读取文件系统的所有block,并检查文件系统是否还处于正确的状态,再来修复。所以日志有快速恢复的属性。
- 高性能(high performance),原则上来说,它可以非常的高效,但是在xv6并不高效。
log块保存在固定的磁盘块中,已经在superblock中标识。在superblock中记录了log块的开始索引以及log块的数量,log块总共有30块(2-31)。
通过crash safty部分得知,文件系统调用对所有磁盘块的修改是不能在写入的中途发生系统crash。因此在日志设计中,将一系列磁盘的写入操作,包装成了一个事务,将所有磁盘块的写入,转换成了对log块的写入。接着了解一下日志事务的过程。
日志事务
将写入操作的分装成事务以及将日志事务产生效果的过程如下,主要有四个步骤:
- 日志写入(log write),将直接写入磁盘块,改为写到log块。假设我们在内存中缓存了bitmap块,也就是块45。当需要更新bitmap时,不是直接写block 45,而是将数据写入到log块中,并记录这个更新应该写入到block 45。对于所有的写 block都会有相同的操作。
- 操作提交(commit op),在某个时间,文件系统的写操作结束了,比如说4-5个写磁盘块操作都结束,并且都保存在log块中,我们会提交这些写操作,也就是提交事务。这意味着需要在log的某个位置记录属于同一个文件系统的操作的个数,例如5。
- 安装日志(install log),安装日志就是将log块区域保存的所有要修改的磁盘块,转移到对应的磁盘块,比如说log5块保存的是595块的写入数据,那么就是将log5块复制到595块,依次安装所有日志。
- 清理日志(clean log),完成安装日志后,就可以清除log块。清除log块实际上就是将属于同一个文件系统调用的操作的个数设置为0。
以上便是日志事务的所有工作流程,接着讨论一下可能发生的crash点。
日志与crash
- 在1和2之间发生crash,重启之后什么都不会发生,就像是在执行文件系统调用之前的状态一样。
- 在2和3之间发生crash,这时所有的写操作都保存在log块中,已经有
committed的标记,重启之后就再次执行install log操作就可以了。但是在2过程中crash,就没有committed标记,重启之后,就像是没有写入一样。 - 在3执行的过程和4发生之前发生crash,下次重启的时候,我们会redo log,我们或许会再次将log块中的数据再次拷贝到文件系统。log中的数据是固定的,我们就算重复写了文件系统,每次写入的数据也是不变的。这就说明
install log操作是幂等的(idempotence,表示执行多次和执行一次效果一样)。
以上便是日志在xv6实现的方式,也是最简单的日志实现方式。
数据交互过程
如下图所示是log write与log install的过程,例如,通过write系统调用,要写入数据到文件中,主要过程如下:只以读写bitmap块为例
- 读取块2(磁盘中日志块编号是2-32)与块45到
bcache,分别为日志头与bitmap块。 - 在内存中bcache修改两个块后,触发log commit,这时就将bcache中的块45与块2写入到log块中(写入磁盘)。
- 之后的某个时间点触发log install,将log块中的$D_{b1}$,其中b1指的是逻辑块,就是一个文件的数据块序列号,比如文件的数据保存在块400,450,460,那么b1=400,b2 = 450,b3 = 460。那么此时b1保存的数据就是块45的数据,直接写入到磁盘块45就可以了
如下图所示H代表log header,其保存block数组内容是箭头H指向的左上角的矩形框中的数据,图中的流程如上面三步骤。

代码:logging
日志结构
在xv6中设计的log结构:
- logheader结构:其中n表示本次log要操作的block数量,block数组代表要写入磁盘block的编号。在
param.h中定义了一次事务中log最大的block数量。 - log结构:主要定义了关于log磁盘块相关的元数据,比较特别的是xv6将日志头嵌入了log结构中,第一个log磁盘块保存的就是logheader。
- log对象:对于日志这个数据对象在xv6中只有一个,一次在并发的事务执行时,需要使用sleep-lock用来解决竞争。
1 | ----param.h |
日志封装
如前面的日志介绍,xv6将对于磁盘的多次交互操作封装为日志事务,保存读写的原子性,在xv6中就使用了两个接口实现事务的封装:
begin_op:在进行磁盘读写前调用,与并发操作中为保护关键区的加锁一样。调用begin_op会进入死循环,这时进程会处于两种状态:
- sleep等待:(1).当另一个事务正在提交时需要将当前事务进程休眠、(2).当日志块的空间满的时候需要休眠,避免日志块的空间被覆写。只有当另一个进程调用
wakeup执行的时候,该事务才可能会被唤醒,并往下执行操作。 - 执行事务:增加outstanding的数量释放log锁,跳出死循环,正常执行磁盘读写操作。
1 | void |
end_op:当磁盘读写操作执行完毕后,调用end_op相当于释放锁的操作,此时将outstanding-1,那么就可以开始提交事务。end_op调用时同样有两种状态:
outstading==0:说明日志结束时,log系统当前进程在进行事务操作并结束,那么此时就可以进行事务提交操作。outstading!=0:说明在日志系统中,同时有两个进程在进行log事务操作,一个事务结束的时候,outstading!=0就说明另一个事务正在执行,那么当前事务就不能提交(主要原因是为了提高log块的利用率)。接着便唤醒(wakeup)休眠进程,因为如果还有进程在begin_op等待,并且log.lh.n的值小于10,那么在begin_op休眠的进程便会被唤醒。如果log.lh.n大于10,那么休眠的进程仍然会休眠,指导当前log事务提交。
1 | void |
Q1:为什么log.lh.n<10的时候,在begin_op休眠的进程就会被唤醒呢?
A1:在begin_op有这样的判断log.lh.n + (log.outstanding+1) * MAXOPBLOCKS > LOGSIZE,可以由此计算得出,虽然是一个判断条件,却有两个束缚,只有当日志块少于10的时候,才能够支持两个进程并发执行log事务。
Q2:两个log并发执行事务,难道不会耗尽log块的空间吗,例如两个进程同时修改磁盘的15以上的块?
A2:在write系统调用函数(kernel/file.c:filewrite)中,一次事务修改磁盘块的大小有所限制,这样就不会导致空间被耗尽。
- 日志写入
由于日志事务存在,xv6就不能够直接使用bwrite将bcache的修改数据直接写回磁盘块。取而代之的是使用log_write()函数:简单来说就是在log结构中记录下修改的磁盘块的编号。
这样做的是方便在后续的提交操作中文件系统将bcache中已修改块先保存到磁盘log中,保证事务操作的原子性。
1 | // log_write() replaces bwrite(); a typical use is: |
- 提交操作
commit:在end_op中,会调用commit函数进行事务提交,主要的流程如下
write_log:将bcache修改的块写入到磁盘log块上。1-write_head:将log数据对象写回磁盘块,是真正的日志提交点!!!install_trans:将磁盘log块的数据写回目标的磁盘块上。2-write_head:清空当前log事务
1 | static void |
write_log:这个函数并不难,理清from与to两个buf的含义。
- from:是在bcache中保存的事务操作中,对目标磁盘块已修改的数据。
- to:是磁盘log块,编号是2-31。
那么这里的意思也就是将内存保存的已修改的磁盘块,写到磁盘log块。
1 |
|
write_head:这个函数有两个作用,先介绍第一个作用。
- 作为提交点:就是将内存中log数据对象的写回磁盘块2,也就是磁盘log块的开始编号,主要是
logheader保存的目标磁盘块的编号。在下述代码块中bwrite将log数据对象写入log块,也就代表的是日志事务的提交点。
1 | static void |
在bwrite发生前出现crash,那么整个事务就视为报废,重启后也不能事务还原。在其之后发生,那么这个事务也就代表成功执行了。这里也就很好的体现了事务的原子性。
- 安装事务
install_trans:这个函数发生在日志提交点之后。在事务成功提交后,xv6就可以放心的将log块中保存的数据写回目标磁盘块了。下述代码也就是将磁盘log块的数据写回目标磁盘块,理解起来也十分的简单。
1 | static void |
- 清理日志
write_head:这里介绍其第二个作用
- 清理日志:在调用write_head前,我们首先将
log.lh.n重置为0,那么就代表磁盘块2中保存的logheadr的n字段也被置为0,那么这里write_header作用就是,防止在此后发生crash后,xv6重启后又重新安装日志。
1 | void commit() |
crash恢复
当xv6遭遇crash时,那么在重启xv6时就会重新读取磁盘log块,重新安装日志并将清除日志头保存的内容。
1 | static void |
Inode layer
简介
inode布局
inode是文件系统的术语,主要有两个相关的意思:
- 指包含文件大小和数据块的编号,在磁盘上(on-disk)的数据结构。
- 指包含磁盘inode和额外的内核信息,在内存(in-memory)上的数据结构。
在xv6磁盘的布局图中,inode是32-45在磁盘上的14个连续的块。每个inode有固定的大小64字节,一个磁盘块有16个inode(1024/64 )。那么给定一个inode号(i-number或inode-number),系统就可以计算得到inode所在的磁盘块的编号。在xv6中公式为:$32+x/16$,例如,i-number=17,那么所在的block就为$32+17/16= 33$。
on-disk inode
on-disk inode数据结构包含的内容如:文件大小、文件类型(目录、文件、特殊文件)、链接数量(指向inode的目录数量)、指向磁盘数据块的地址的指针(有直接、间接地址,实际就是磁盘块编号)等元数据。以下便是磁盘中保存的inode结构,xv6的实现省去了文件创建、修改时间等等信息。
1 | ----fs.h |
xv6的inode有12个直接地址指向12个数据块,1个间接地址指向1个块(数据块),这个数据块包含了256个块号(1024/4 = 256,除4是因为块号的数据类型为uint32,block number)。由此可以计算得到xv6中可以存储文件的大小最大为$(12 + 256) * 1024 = 268KB$,由此可见xv6中可以容纳的文件大小特别的小。现在inode的地址字段布局如下所示。

在fs实验中会要求能够存储大文件,超过268KB。具体的实现思路为使用两级间接指针,类似于三级页表一样,就是一级间接地址(inode保存的一个间接地址指针)指向保存的是256个二级间接地址的块,每个二级间接地址指向一个保存256个块号(uint32无符号整数指向数据块,block number)的数据块,具体的指向如下图。在该实验中就会实现前11个指针为直接地址,第12个为一级间接指针,第13个位二级间接指针,那么此时可以容纳最大的文件大小为$(11 + 256 + 256 256) 1024 = 64MB + 12KB $。
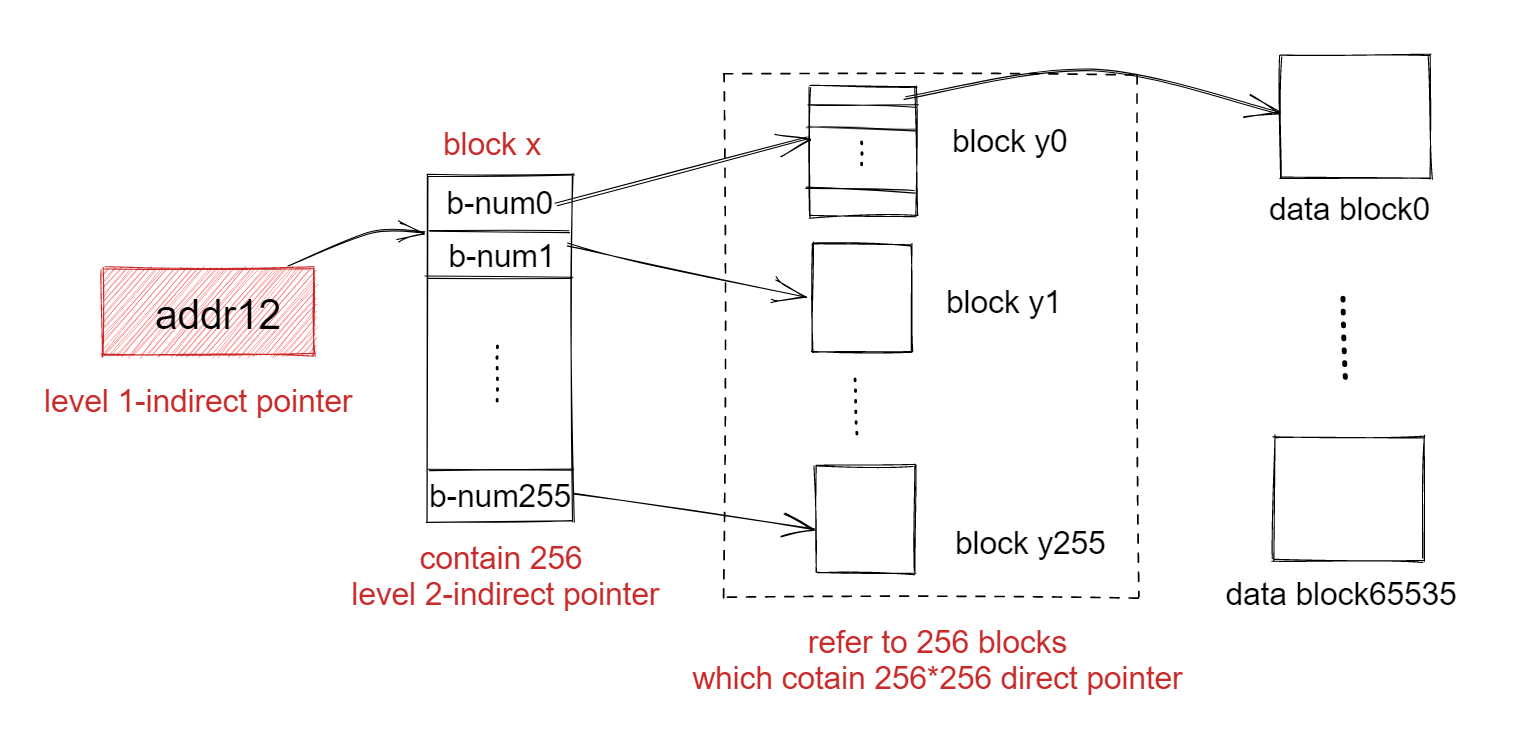
那么现代操作系统下可以保存几十个GB的文件,那么inode的地址字段又该如何设置呢?没错就要使用三级指针,这样也和三级页表更相似了。
inode锁设计
在xv6中实现了两种inode锁和两个锁风格的机制用于保护inode结构。
- itable.lock,是自旋锁,保护inode内存表中最多出现一次inode的不变量(内存inode的ref字段,记录内存中有多少个指针指向该inode)
- inode.lock,是睡眠锁,每一个inode都有一个这样的锁,确保独占的访问inode的字段(如长度)和inode指向的文件或目录内容。睡眠锁可以很好了解放CPU占用问题。
- ref字段,记录引用该文件的进程数,如果
ref>0,inode会继续保存在itable中,并且不会将该itable的条目用于其他inode。 - nlink字段,用于计算目录的文件(如不同目录路径下引用的这个文件)指向该文件的条目数,同样的
nlink>0,inode会接续保存在itable中。
以下便是itable的结构,还是比较简单的,就是一个inode数组和自旋锁而已,由于itable保存于内存中,其保存的inode数量只有50个,是少于磁盘保存的inode数的。
1 | ----fs.h |
代码:Block allocator
块分配器的相关操作:
块分配器提供了两个函数用于操作空闲池:
bfree:释放磁盘块,设置bitmap,标记指定磁盘块位空闲:
- 使用
bread通过inode读取文件的磁盘上bitmap块,并缓存了buffer cache的节点 - 更改bmap块的指定文件数据块号的位的值,将指定位设置为9。例如要删除
block number = 60的块,只需要将第一个bitmap块(60/(1024*80) = 0,使用BBLOCK计算)上,第8个字节(60/8 = 7,使用BPB计算,字符数组从0开始计数),将第8个字节上的第5个位(60%8 = 4,同样是从0开始),设置为0就可以了。 - 调用
log_write,将该inode块的写入操作添加到log header。
1 | ----fs.h |
balloc:分配磁盘块,设置bitmap,标记指定磁盘块已分配:
这个函数于bfree函数的实现思路相同,都是操作bitmap块,只不过效果是相反的,这里就不过多阐述了。
代码:Inode分配
in-memory inode
在buffer cache中保存的inode块是直接拷贝的磁盘上的inode块,但是在为了方便并发控制以及inode数据操作,xv6中设计inode层上使用的inode结构,如下所示,添加了一些字段:
1 | ----file.h |
分配新的indoe
首先xv6调用ialloc,这个函数与balloc相同:如下图所示,遍历磁盘上的所有inode节点,寻找到空闲的inode后,写入inode类型到磁盘,然后通过调用iget从inode表中返回一个条目。ialloc必须确定只有一个进程持有对bp的引用,并且要确定这个过程的原子性,不能同时的被其他进程看见这个inode是可获取的。
1 | ----fs.h |
接着看看如何通过iget将空闲的inode加入inode表(内存的保存的结构)。首先遍历整个inode表,如果这个inode以及存在(ip->ref>0)于inode表中则添加引用计数,并将其inode返回,反之将记录一个空闲inode,退出循环后,分配inode表中这个inode槽。
1 | ----fs.c |
以上过程便是ialloc分配ialloc过程,,将磁盘的inode块读取到buffer cache中,并从buffer cache获取一个空闲inode,将其记录到inode表中,并返回这个inode地址。
如果你看过创建文件的代码后,就可以知道在用户使用open系统调用时,进入内核便会调用create创建文件,接着会调用ialloc为该文件分配inode。
inode锁
在读取或写入inode的元数据或内容之前,必须使用锁来预防数据竞争。inode锁的使用方式是ilock与unilock。
ilock使用睡眠锁(sleep-lock)保护inode。一旦ilock独占的访问inode,如果需要就可以向磁盘读取(更多的是向buffer cache读取)inode。iunlock释放睡眠锁,可以让唤醒一个因等待该inode资源的进程。
1 | ----fs.c |
代码:Inode释放
iput:释放inode
iput:如果inode没有其他指针引用(ip->ref == 1)并且没有目录链接(ip->nlink == 0),这个块将会被释放。
1 | ----fs.c |
itruc:释放inode指向的文件数据
itrunc:在iput中会调用该函数,将文件截断为0字节,释放数据块,将inode的type字段设置为0(代表该inode未分配),最后将inode写回磁盘。
1 | ----fs.c |
iput:锁与类似于锁的机制
接着研究iput是如何释放inode锁定协议的,主要运用了两个锁和两个类似于锁的机制机制解决。
首先第一个问题是,并发线程为了使用inode可能会在ilock等待,并且没有发现这个inode不会再被分配,就是没有在并发线程知道的情况下释放了inode,但是这不会发生,主要是因为如果inode没有目录链接(ip->link == 0)并且ip->ref == 1,系统调用没有方法获取内存inode的指针。而且唯一的引用还是调用iput的线程的引用数,所以调用iput之后检查inode的引用计数是否在itable.lock的关键区之外,但是此时链接数量为0,所以说明没有其他线程尝试获取这个inode。
另一个点是,并发调用ialloc可能会选择相同的并且正在被iput释放的inode,这个只可能发生在iupdate写入inode到磁盘之后,这时inode的type字段为0。但是这个数据竞争是良性的,分配inode的线程在读取或写入inode之前,会等待以获取inode的睡眠锁,直到iput释放。
iput可以写入磁盘,这也就意味这任何系统调用会使用文件系统写入磁盘,因为系统调用可能是最后一个文件引用的调用。read系统调用以只读的方式读取文件都会在结束之前调用iput,这就意味则所有的文件系统调用将会封装到事务中。
挑战:crash与iput
问题:crash与iput的交互是一个挑战,因为一些进程可能持有内存inode的引用,所以iput当文件的链接数为0时也不会立即的截断一个文件。但是如果crash发生在最后一个进程关闭文件文件描述符之前,然后文件才被标记,但该文件已经分配到磁盘但是没有目录条目指向这个文件,在内存inode写回磁盘时crash,就会有磁盘中有残留的文件数据。
文件系统解决上述问题,主要有两种方式:
- 从恢复(recovery)方式上解决:在重启之后,文件系统扫描整个已经标记分配的文件,但是没有目录条目指向,此时只重新为文件添加目录条目就可以了。
- 从锁机制上解决:文件inode的inumber的链接计数下降到零,但是引用计数却不是零。如果当文件的引用计数到达文件系统删除文件,然后通过从列表删除inode更新磁盘列表。在恢复上,文件系统将会释放所有在list中文件。
xv6没有实现上述两种方案,这也意味这上述的错误情况可能会发生在xv6中。
代码:数据块分配
在为文件添加数据时,通常会创建新的数据块。查看write系统调用,就可以知道创建数据块是调用了bmap函数,在bmap中调用了balloc函数就是用于创建数据块的。
bmap:查找数据块编号
bmap函数中会分别使用直接地址指针与间接地址指针记录数据块号,这些指针记录于inode中。在xv6的文件系统中,ip.addr[0:11]是直接指针地址,ip.addr[12]是间接地址指针地址。bn是用于标记现在要写入数据的块,是该文件的第几个数据块。
- 查找直接地址:如果
bn<NDIRECT,说明所写的数据偏移是小于1024*12(12个块)的。查找该索引的地址是否存在,不存在使用balloc分配数据块,并将这个数据块的编号记录到addr数组中,反之返回addr保存的地址值。 - 查找间接地址:如果
ip.addr[12]存在,那么就可以直接读取这个保存数据块地址的地址块(address block,这个块也是一个数据块),使用balloc分配数据块,并将其记录到地址块的指定索引中。反之不存在就使用balloc分配地址块。
1 | ----fs.h |
通过使用bmap函数便readi与writei可以很方便的操作数据块了。
Directory layer
简介
在linux中目录(dircetory)被设计得像文件一样,本质上就是文件加上一些文件系统能够理解的数据结构。在inode中的type字段为T_DTR则说明是一个目录,并且这个inode会保存目录条目,可以是文件或子目录,这些目录条目则保存在目录inode的地址指针指向的数据块中。
每一个目录都会包含多个目录条目,如下结构体便是目录条目(directory entry)。长度为16字节,分为如下两个字段:
inum(2B):子目录的inode编号;name(14B):文件或者子目录的名称。
由此可知一个数据块能够保存1024/16 = 64个目录条目。
1 | // Directory is a file containing a sequence of dirent structures. |
接下来介绍以下与目录相关的代码。
代码:directory layer
dirlookup:查找指定文件
通过指定的名字在目录inode中查找对应的目录条目,如果找到指定的目录条目就将返回对应的文件inode指针,将*poff设置为当前的目录条目偏移量,以便调用函数可以修改这个条目,最后通过iget返回一个未锁定的inode指针。
1 | ----fs.c |
dirlink:添加文件inode到目录inode中
在使用open创建文件时会使用到该函数,通过传递给定的名称和i-number作为一个目录条目到目录inode(dp)中。主要步骤如下:
dirlookup判断要添加的目录条目inode是否已经存在于当前目录inode中,存在的话则返回一个错误。- 遍历
dp指向的保存目录条目的数据块,寻找一个数据块中是否有空闲的目录条目节点,若找到则跳出循环。 - 将传递的参数写入空闲目录条目中,再将目录条目写回数据块。
1 | ----fs.c |
Pathname layer
代码:Path names
在操作文件的时会涉及一系列的路径名,如相对路径、绝对路径、当前路径等。只有指定了正确的路径名我们才能打开正确的文件,因此通过路径查询文件也是十分重要的功能,在xv6也提供了路径名解析的函数:
namei:解析路径名并返回指定的inode
namei是输入一个路径名参数,以此解析路径获得文件inode。如:输入/a/b/c,那么获得的就是文件c的inode。
1 | struct inode* |
nameiparent:返回文件父目录的inode
nameiparent是namei函数的变种,与其不同的是需要输入两个参数,会返回父目录的inode并将路径名的最后一个元素保存到name中。例如输入/a/b/c,name就是c这个文件,而inode则是/a/b这个目录inode。
1 | struct inode* |
namex:解析路径函数
namex是namei与nameiparent函数的广义的函数,实际上所有的解析操作由namex完成。接着按照流程解释一下namex构成:
- 判断路径名开始字符,确定路径名,如果是以
'/'开始就是绝对路径,为开始读取根inode),反之是当前路径,读取当前进程的inode。以此获得目录inode。 - 循环执行
skipelem函数,解析路径名称跳过一些目录或者重复的元素(如'/'字符)。 - 如果
path=/a/b/c,经过skipelem调用后path=b/c。显然path并不为0则进入循环,在循环内部首先检查ip这个inode是否为目录,如果不是则调用iunlockput函数释放inode。再判断调用者是否为nameiparent函数并且path是否为0,是的话则返回这个目录inode。 - 判断文件名(
name = /b/c)是否在目录inode(根目录/)中存在,如果存在获取/a/b/目录的inode,并将ip设置为当前inode。
以/a/b/c为例,那么第一次循环path = b/c,name = a ip = a/,第二次循环path = c,name = c ip = b/,第三次循环path = 0,name = c,退出循环。
1 | static struct inode* |
File descriptor layer
简介
Unix设计中比较意思的方面就是在Unix中的大部分资源都可以表示成为文件,包括设备(console),管道,文件。File descriptor layer则是将所有资源统一为文件的层,体现了一致性(uniformity).
文件描述符从数据类型的视角来看就是一个整型int,通过文件描述符我们就可以调用write或read方法去操作文件资源。但是文件描述符的背后的数据结构并不是一个整型所能表述的,文件描述符是通过层层抽象得到一个简易的可以操作文件资源的句柄,实际原理是将文件的inode与文件描述符通过内核制作成了一个映射。
那么在xv6是如何通过文件inode一步步生成文件描述符,又是如何通过文件描述符操作文件的,接着学习一下有关File descriptor layer的代码。
代码:文件结构
1.进程结构
进程的结构体代码,我们会发现proc结构体有两个关于文件的字段:
- ofile:表示进程已打开的文件或文件描述符表,每一个file结构对应一个文件描述符。那么NOFILE==16,也就代表xv6中能够一个进程最多能够打开16个文件。
- cmd:cmd代表当前进程的文件目录的inode。
1 | ----proc.h |
2.文件结构:保持Unix资源一致性
在xv6内核中,为了方便管理文件、设备、管道等资源、将这些资源抽象一致化为文件,设计成为了file结构体。
每个打开的文件都由一个struct file 表示,对 inode或管道以及 I/O 偏移量等元数据的封装,不同类型的资源可以使用type字段进行标识。在用户进程每次调用open系统调用创建新文件的过程,就是创建一个新的struct file。file结构在多进程同样也可以很好的协调:
如果多进程独立打开同一个文件,不同的实例的I/O偏移量也不同
另一方面,一个打开的文件可以多次出现在一个或多个进程的文件表中,如果一个进程使用 open 打开文件,然后使用
dup创建别名(单进程文件表),或使用fork(多进程文件表)与子进程共享,就会出现这种情况。
文件结构体代码,如下所示:
1 | ----file.h |
3.全局文件表:
所有以打开的文件,都会保存在系统的全局文件表中(ftable),在ftable中提供多个函数接口给内核,用于操作全局文件表:
filealloc:分配文件。filedup:创建重复的文件引用,增加文件引用数。fileclose:释放文件引用,当引用数为0,释放文件。fileread、filewrite:对文件进行读写。
1 | ----file.c |
全局文件表的主要作用:用于多进程之间文件实例的通信、内核可以更加方便的使用文件资源。
代码:创建文件描述符fd
1.用户级文件操作示例
如下所示,在用户程序中,可以使用open进行创建文件,并且获取文件描述符fd。那么fd就代表这个test1文件。之后我们便可以通过这个fd访问文件,使用write向test1文件写入内容。
1 | ----user/test1.c |
接着以系统调用操作的顺序进行了解。为了不混淆文件之间的概念,在此先声明下文所提每一个词汇的所指向的实体:
- 文件实例:数据类型为
struct file,已打开的文件在全局文件表中保存,其保存的inode字段指向了文件资源。 - 文件资源:主要用于表示磁盘块上的文件数据,内核就是通过文件实例中的inode字段,访问到文件资源的。
- 文件描述符:用户级的文件实例,数据类型为
int,是简化过后了文件实例,作为进程文件表的索引。
以上是笔者自己的表述(不包含设备和管道的描述),可能有所毛病,如有错请指出。
2.open:获取文件描述符
- 用户通过open系统调用输入的路径(
./test1),在sys_open创调用create函数,创建了当前目录下的文件(test1)的inode。 - 调用
filealloc分配全局文件表,分配一个文件实例。 - 调用
fdalloc将上述获取的文件实例转化成为文件描述符,这可以理解建立了映射。 - 设置文件实例的相关字段,这里主要是将test1文件的
inode绑定到了文件实例上。 - 将文件描述符返回给用户。
1 | ----sysfile.c |
3.分配文件描述符:建立文件实例映射
fdalloc函数:观察下述代码,主要是将全局的文件实例,分配给了当前进程,fd则是代表的是进程打开文件表(open file table)的索引。那么在此之后只要是该进程的用户进程就能够通过这个文件描述符,访问到对应的文件实例。原理就是简单的hash表。
1 | ----sysfile |
以上过程粗略的可以描述为下图:

代码:通过fd修改文件资源
4.write:通过文件描述符操作文件
在通过open获得test1的文件描述符fd后,那么wrtie就可以通过fd去修改文件数据了。具体的过程就是通过argfd函数将fd转换为文件实例,在通过文件实例中保存的test1的inode字段,就可以对文件数据进行修改。
之后在调用filewrite就能够将write系统调用传入的字符或字符串,写入到test1文件中了。
1 | uint64 |
5.获取文件实例:根据文件描述符获取对应文件实例
在前文也提到了,通过argint获取用户传递的fd,将fd作为当前进程结构的ofile字段的索引便能够得到文件实例,这样sys_write函数就能够获得文件实例。
1 | ----sysfile.c |
6.修改文件资源:通过文件实例的inode字段,访问并修改文件资源。
如下述代码所示,这里我们忽略掉设备和管道等文件类型,只关注inode文件操作。在代码中,filewrite函数调用了writei函数,注意到writei中将文件实例的inode字段作为参数进行传递,也就说明writei函数是根据inode对文件资源的描述,对文件资源进行修改的。
1 | int |
总结
文件系统算是操作系统中代码量比较大的一个部分,在学习上也需要配合代码来理解。由于文件系统的体量比较庞大,在学习上也比较困难。在xv6中将文件系统抽象成了7个层面,通过每一层执行不同的功能,在通过操作系统的协调,由繁至简便能够更好的去理解文件系统。
在本章的学习过程中,比较难以理解的就是Buffer cache、Logging、Inode三个层面。其他的代码量也相对比较少,在此总结一下每一个层面的内容:
- Disk layer:对磁盘数据资源按功能进行范围划分,有boot、super、log、inode、bitmap、data等类型的磁盘块,磁盘的两个扇区算作一个块。
- Buffer layer:将内存的一部分作为磁盘块的缓存区,加速CPU对磁盘数据的修改。在该层涉及到了双链表与LRU的操作,虽然简单,但还是比较值得学习的。
- Logging layer:提供数据库中的事务与日志概念,在xv6中实现log,主要是为了防止crash问题,以实现修改磁盘数据的原子性(数据库的概念)。
- Inode layer:Inode是描述文件的一个数据结构,通过inode可以获得文件的基本信息,在Inode层比较需要理解的就是文件指针(用于定位文件磁盘的数据块)、内存inode与磁盘inode的区别、以及内存inode的操作。
- Directory layer:通过目录的概念,将文件的存储设计成了分级树状的结构。
- Pathname layer:将一个文件路径名(如a/b/c)通过解析找到对应的文件(c)inode,对文件进行操作。
- File descriptor layer:将Unix大部分资源一致化,抽象化为文件形式(
struct file)。提供给用户进程的一个文件实例,通过文件路径名并能够获得文件资源句柄,用户进程可以通过该句柄访问指定的文件进行操作。
以上便是xv6文件系统的所有知识点了,建议在学习过程中配合源码进行理解。