Mit6.S081:lab locks
实验:Lab: locks
实验开始之前需要将git分支切换到locks分支不然有些文件你是没有的
1 | $ git fetch |
Memory allocator(moderate)
简介
在kalloctest程序会对内存分配器进行压力测试:三个进程测试点会增长和压缩内存空间,该过程中多次调用在kalloc.c文件中的kalloc()与kfree(),这两个函数又会多次调用锁(kmem.lock)。这时会造成锁的竞争(lock contention),也就是多个CPU一起竞争想要获取同一把锁,这样会导致CPU资源占用从而影响性能。
注意锁竞争(lock contention)与数据竞争(data race)是不同的:虽然两者都是并发中的概念,但是锁竞争只会影响并发的性能,而数据竞争会造成数据的完整性与正确性,通常使用锁来保证数据不被竞争。
在kalloctest运行时,会打印acquire调用(获得kmem.lock)次数与锁竞争(尝试获得kmem.lock)的次数,如下面打印结果所示:#test-and-set后的整数是锁竞争的次数,#acquire()后是调用acquire函数的次数。
1 | $ kalloctest |
在kalloctest的test1中,要求锁竞争的次数不超过10次,这也是本次实验设计的重点。
那么该如何减少锁的竞争?实验中给出的提示是让每个CPU有一个freelist与锁。锁的作用暂时不说,讲解一下kmem.freelist:从kalloc.c中的定义以及freerange可以得知,freelist就是一个没有数据域的管理空闲的物理页链表,每个节点指针域是指向物理页的开头的,因此也可以知晓一个节点的大小是一个物理页长度(4096)。
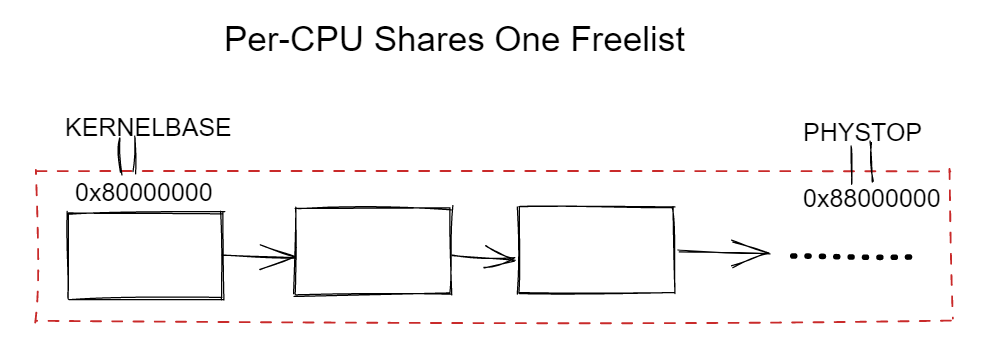
共享freelist
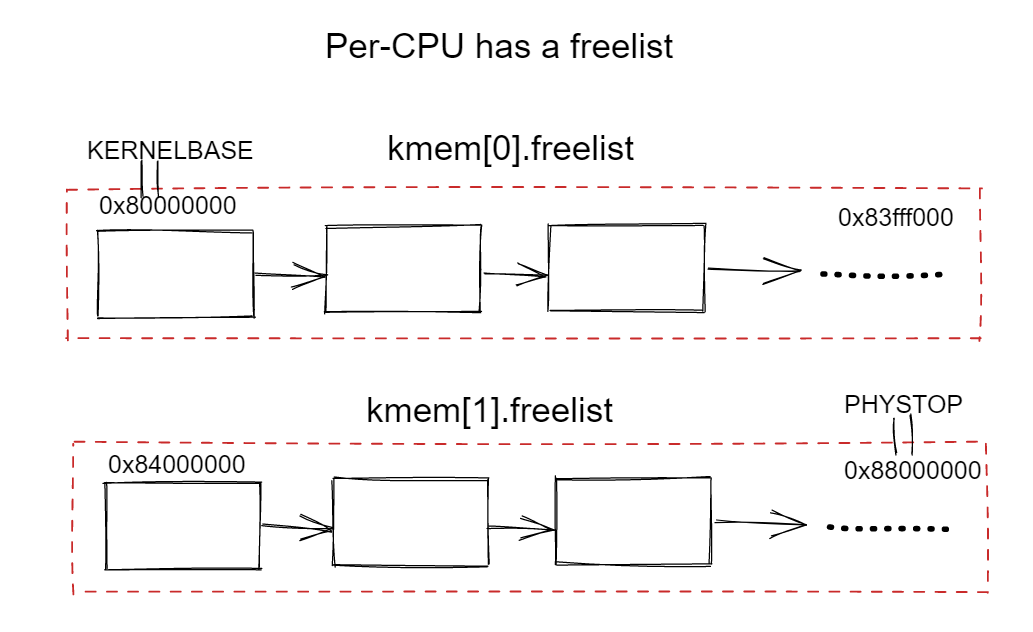
从下图中可以得知每个CPU都在共享一个freelist,使用锁避免数据竞争。但是每个CPU申请物理页都在操作一个freelist,这时就会造成锁竞争。
独立freelist
如下图所示,以两个CPU为例,我们让每个CPU拥有一个freelist,简单来说就是将一整个freelist按可用地址空间大小(kernelbase-phystop)划分为两个部分:
- 0x8000000-0x83fff000:第一个CPU的freelist
- 0x8400000-0x8800000:第二个CPU的freelist
这样的话就将一个freelist独立开来了,后续还可以根据CPU数量来划分多个独立的freelist。
为什么要每个CPU有一个锁?
因为每个CPU的freelist是独立的,所以当一个CPU的freelist为空后,该CPU又调用kalloc函数会返回0也就是分配失败,这种情况显然造成的性能损失更大。
当前CPU的freelist为空后,kalloc需要提供一种功能,能够获取其他CPU的freelist的一个物理页节点,在实验中这种功能称为steal窃取,那么我们的锁也是在此时会起到作用。
例如两个CPU共同竞争同一个CPU的freelist资源时就会有数据竞争,那么锁也在此时起到了作用。
具体的实验要求与实验提示,不过多赘述,没有看文档的同学,阅读一下locks实验文档。
实现
这个实验主要是在kalloc.c文件中完善相应的实现,需要实现每个CPU有独立一个链表有一个独立的锁。
1.修改kmem为数组:每个CPU有一个独立的锁与freelist
1 | struct { |
2.初始化每个CPU的freelist
在kinit中需要将freelist的节点指向每个物理页的起始地址,这时也需要修改freerange的范围。
- 将整个内存空间切割为NCPU个块(chunk),每个CPU管理一个块的内存
- 初始化每个CPU的锁(
kmem[id].lock) - 确定每个CPU管理内存的起始于结束地址
- 传递值给
freerange,在其中调用kfree将对应范围的物理页添加到给freelist
1 | void |
3.修改:释放物理页kfree
在之前也提到了,steal阶段会产生竞争。那么steal阶段与kfree阶段同时进行时也会产生竞争。这时要使用到对应CPU的freelist的锁了,由于其他CPU就算steal了物理页其物理地址也是不变的,那么steal该物理页的进程释放steal的物理页也是调用kfree。
- 在kfree中我们需要保证这个物理页准确的归还到被steal的CPU的freelist中,所以我们需要根据传入的物理地址判断所处的范围,进而判断CPU的id,最后通过加锁并将物理页归还到原来的CPU的freelist中,再释放锁就可以了。
1 | void |
- pa2cpuid:该函数是用于判断物理地址范围,这个返回根据kinit的freerange的范围各有所不同,最后返回管理该范围的CPU的id号。
1 | int |
修改:分配物理页kalloc
- 分配物理页过程不需要过多的修改,只是新增一个判断,当当前CPU的freelist为空后,就需要向其他CPU进行steal了,steal得到的物理地址直接返回即可。
1 | void * |
新增:窃取(steal)物理页
- steal过程原理上是比较简单的,就是遍历所有CPU当有空闲节点时就返回物理页的地址,但是需要注意的是,修改其他CPU的freelist过程是需要加锁的。
1 | void* |
完成以上实现就可以通过kalloctest测试了,但是极少情况下test1也会FAIL(超过十次锁竞争)。主要原有是并发测试是多次steal也会导致锁竞争,还有就是在测试之后发现qemu开始的CPU数量是3个而NCPU=8可能会引起多次steal。但是实验的大致意思也就是这样,如果大家有改进思路也可以提出。
buffer cache
简介
NOTE:在做该实验时,如果没有阅读xv6的8.1-8.3章节和bio.c代码的读者请阅读完后再做该实验。
buffer cache介绍
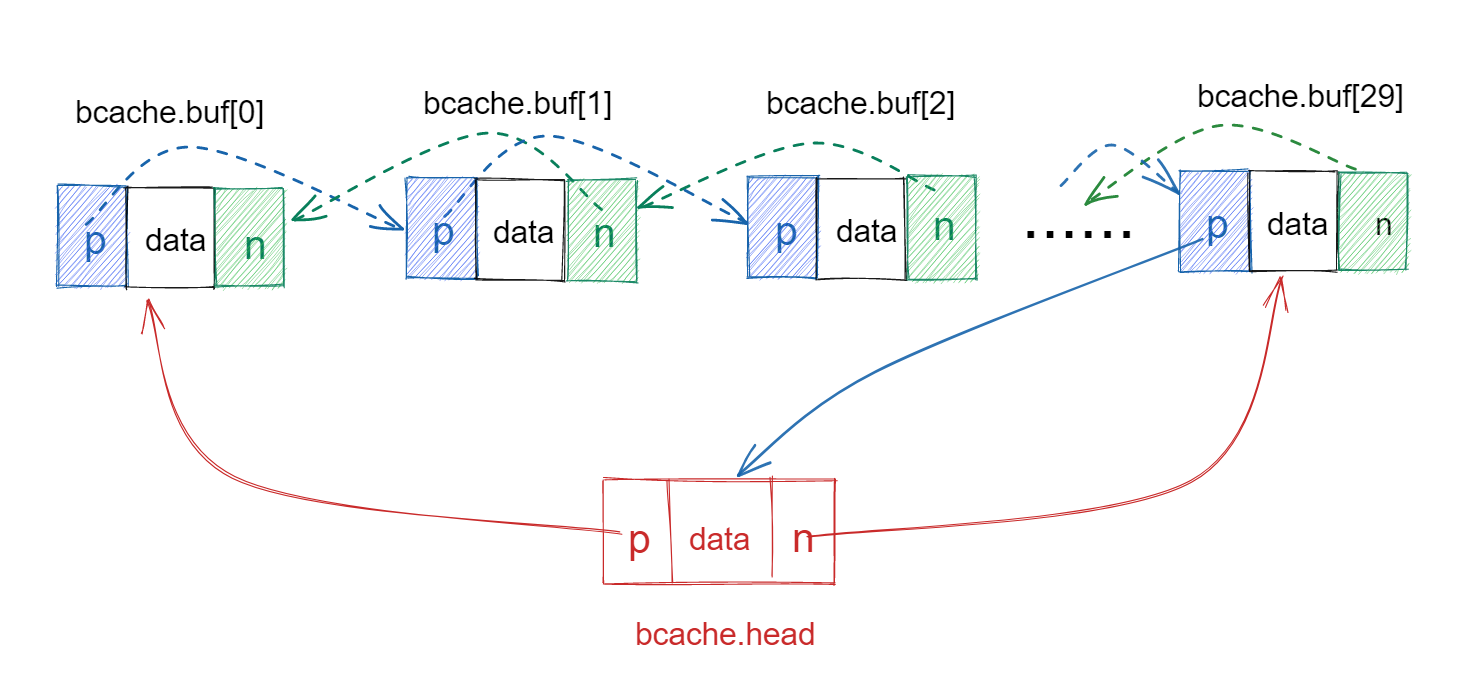
buffer cache是文件系统组织中的一层,主要功能是缓存磁盘数据到内存中加速访问。在bio.c的bcache结构体中使用一个bcache.lock保护了30个buffer节点,也实现了LRU链表,如下图所示。
实验问题:
有了上个实现提供给我们的思路,也就发现了本次实验的问题所在,那就是对单个资源使用一个锁是会导致锁竞争的。也就是xv6对buffer cache(内存资源)只使用一个锁,保护了30个节点的资源竞争,从而造成了锁竞争。
在kalloc的实验中确定了只有固定的CPU线程会使用kmem资源,因此很容易拆分资源。但是buffer cache却不同,多个用户进程会共享同一个buffer资源(给每个CPU设置一个buffer分配器,同样会导致锁竞争)。这样的也导致buffer cache是难于kalloc实验的。
实验解决思路:
解决思路同样是将资源进行拆分,这次需要使用哈希表(hash table)。哈希表中设置素数(实验提示使用13这个素数)个桶(bucket),每一个桶内设置放置一些buffer,并且每一个桶都有一个独立的锁。那么当使用bget获取buffer时,只需要将磁盘块的编号进行hash,返回一个整数作为哈希表内桶的编号,并在桶中找到指定的buffer。
HINS:
- 在实验中不需要实现LRU链表或是LRU算法了(在以前的实验中要求使用时间戳实现该功能),因此在
brelse中不需要处理refcnt==0的情况了。 - 在
bget中当指定桶没有空闲的buffer时,需要向其他桶偷取(steal)空闲的buffer,像kalloc一样。 - 在查找、修改每一个桶的buffer时都需要保证这个操作是原子性的。
实现
新增:bucket结构
bucket结构体中只有两个成员,锁和buf链表的头部。- 将
bcache中原有的head与lock删除,新增buckets成员,也就是13个bucket结构体数组
1 |
|
新增:hash
该函数采用模运算的方式,将指定的设备号和磁盘块号通过运算转换为桶的编号。
1 | int |
新增:插入buf到bucket
采用头插的方式将buf插入到指定的bucket中。
1 | //head insert |
修改:binit初始化bcache中的bucket
- 初始化每个bucket的锁
- 将30个buffer放入都放入第一个桶(
bcache.buckets[0])中制作为一个链表,但是此时我们只需要next执行遍历就可以了
1 | void |
修改:bget获取buf节点
bget是本实验最难的一个环节了,并发冲突主要也出现在该函数中,实现流程如下:
- 通过输入dev和blockno获取一个hash值,也就是bcache桶的编号。
- 获取指定的buffer桶的锁,遍历桶中的buffer节点,如果以及buf已缓存就函数返回,在此过程中需要使用
idle_buf记录桶中未缓存的空闲节点,当遍历结束之后如果有空间节点就返回。 - 如果指定编号的桶没有缓存的buf节点,并且没有空闲buf节点,此时需要向其他桶偷取空闲buf节点。
- 将偷取回来的节点添加到这个桶中,并调用
buf_update更新该buf节点的相关元数据,将最后返回锁定的buf。
1 | static struct buf* |
完成上述的代码其实就能够通过实验了,但实际上上述代码会有一个问题:并发读取一个块的时候,两个buffer会同时缓存一个磁盘块。
只不过在实验指导文档说明了,bcachetest程序不会区检查这个冲突的
When two processes concurrently use the same block number. bcachetest test0 doesn’t ever do this.
Q:为什么会并发读取一个磁盘块的时候,会导致多个buf节点缓存同一个磁盘块呢?
A:首先有两个进程(P1、P2)同时读取同一个磁盘块,按照序列化,P1通过上述的步骤2,随后P2也通过了步骤2,两个进程都没有在同一个桶内找到buf节点。之后P1、P2要并发地偷取其他桶的空闲buf节点,但是根据偷取过程的原子性,那么返回的节点也就是两个不同的空闲buf节点。返回过后便是要写入节点到桶内了,此时按照上述的代码也就是要写入两次空闲的buf节点,且元数据都指向同一个磁盘块。
再修改:bget获取buf节点
为了放置上述情况的出现也就是说,需要在偷取完成后增加一个检测过程。这个检测过程也比较简单,还是以两个进程(P1、P2)为例。
P1、P2通过偷取过程获得了两个空闲块,此时如果P1先将磁盘块数据写入P1的空闲buf块内,并将偷取buf块加入了桶中。P2后续也准备写入,此时就有一个检测过程,判断是否有进程已经读取了同一个磁盘块(已缓存),如果有就将P2偷取的buf节点(作为一个未缓存buf)放入到桶中,并将查找到的已缓存节点返回。
代码如下所示,通过这样便可以很好的解决了,并发读取同一个块的问题了。
1 | static struct buf* |
steal_buf: 转移空闲buf
该函数主要有两个流程:
- 遍历每一个桶的buffer节点,并查找空闲的buffer(
refcnt==0),这个过程是原子性的,所有需要在查找每个桶时加上对应的锁。 - 找到空闲的buffer后,修改桶的buffer链表结构,也就是将该buffer节点从链表中删除,删除时需要注意修改头指针的指向,并将空闲buffer指针地址返回。
1 | struct buf* |
修改:brelse释放buf节点
brelse、bpin、bunpin的实现十分的简单就是更换锁为指定的桶的锁就可以了。
1 | void |
总结
本次实验难度比较适中,用时比较多的也是在buffer cache部分,主要原因是链表的使用以及使用hash函数的时候输入了dev这个参数,花费了一定的功夫才找到bug。
本次两个实验都是解决锁竞争(lock contention),做完本次实验后也可以发现解决锁竞争的方式就是——拆分单个资源为多个资源,并使用独立的锁进行保护,当然sleeplock也是解决锁竞争的好方法。
在实现过程中重叠使用不同的锁很容易导致死锁,做过mit6.824的实验后也是比较清楚这些问题,比较好的解决方式就是使用同一个锁保护一个关键区(crucial section),不要重叠使用锁。