xv6:操作系统接口
系统调用
在操作系统的简介中,说到为了方便程序使用硬件资源操作系统会提供一些应用接口。
如Figure1.1所示,在xv6中采取一个内核(kernel)空间的设计:一个特殊的程序提供服务给运行的程序。每个运行的程序我们称作为进程(Process)拥有指令、数据、栈。用户空间(user space): 抽象出的一个空间,用于用户运行应用程序,如shell(本质上是一个应用程序,功能就是读取命令并执行)、cat
- 指令(instruction):实现程序的计算
- 数据(data):一些计算的变量
- 栈(stack):组织的程序(C语言中的函数)的调用
当进程调用内核服务时我们就需要进行(invoke)系统调用,系统调用会进入内核,然后内核执行服务并返回,于是这样的一个进程会选择在用户空间与内核空间执行。

进程与内存
进程(Process):
进程的概念:进程简单来说就是正在运行的程序,例如我们以及启动的word办公软件、游戏应用等应用程序。
我们为了实现一个系统能够同时运行多个程序,系统需要提供一种拥有多个CPU的假象,称作为虚拟化CPU
那为了实现这种技术我们采用了一种叫做时分(time sharing) 的CPU技术:一个进程只会运行一个时间片,之后便切换到其他进程,从而提供多个CPU的假象。
进程之间的切换称作为上下文切换(context switch).
进程系统调用:xv6
进程API设计所需要包含的内容
- 创建(create):操作系统必须包含一些创建新进程的方法。在 shell 中键入命令或双击应用程序图标时,会调用操作系统来创建新进程,运行指定的程序。
- 销毁(destroy):由于存在创建进程的接口,因此系统还提供了一个强制销毁进程的接口。
- 等待(wait):有时等待进程停止运行是有用的,因此经常提供某种等待接口。
- 其他控制(miscellaneous control):除了杀死或等待进程外,有时还可能有其他控制。
- 状态(status):通常也有一些接口可以获得有关进程的状态信息。
| 系统调用 | 描述 |
|---|---|
int exit(int status) |
中止当前进程,将状态报告给wait(),没有返回 |
int getpid() |
返回当前进程的PID |
int fork() |
创建进程,返回子进程的PID |
int wait(int *status) |
父进程等待子进程退出(exit);退出状态是*Status,返回值为子进程的PID |
int sleep(int n) |
暂停进程n个时钟ticks的时间 |
int exec(char *file, char *argv[]) |
加载文件(*file)执行,以其参数(*argv)执行程序,错误后返回-1 |
int kill(int pid) |
中止进程号为PID的进程,成功返回0,错误返回-1 |
char *sbrk(int n) |
增加当前进程的内存空间,并返回新内存的开始位置 |
应用示例
创建
使用fork()系统调用,可以创建进程,新创建的进程(child)会复制当前进程(parent)的内存(数据与指令)。fork()创建进程成功后(不同的进程的PID不会相同),子进程的返回值为0,父进程的返回值为子进程的PID退出—-其他控制
使用exit()系统调用,会导致调用它的进程停止运行,并且释放诸如内存和打开文件在内的资源。等待
使用wait()系统调用,会返回一个当前进程已退出的子进程,如果没有子进程退出,wait 会等候直到有一个子进程退出。如果调用该接口的进程没有子进程,会返回-1,当我们不在意子进程的状态时,我们可以传入0去等待。
观看下述代码示例
1 | int pid = fork(); |
上述示例中的运行结果为
1 | parent: child=32381 |
NOTE: 虽然我们父子进程在初始化时会有相同的内存,但是在之后,他们会有单独的寄存器与内存,两个进程的变量彼此互不干扰。例如,对于变量PID,父进程中PID = 32381,而子进程的PID = 0
- 执行文件
使用exec系统调用 ,将从某个文件(通常是可执行文件)里读取内存镜像,并将其替换到调用它的进程的内存空间。
示例:这段代码将调用程序替换为 /bin/echo 这个程序,这个程序的参数列表为echo hello。大部分的程序都忽略第一个参数,这个参数惯例上是程序的名字(此例是 echo)。
1 | char *argv[3]; |
xv6: user/sh.c中我们会开启一个死循环进行读取用户的输入,我们会创建一个进程,将解析完成的参数,传递给runcmd()函数去调用exce执行程序(echo程序),wait是主程序需要等待f子进程的退出。
1 | while(getcmd(buf, sizeof(buf)) >= 0){ |
xv6 通常隐式地分配用户的内存空间。fork 在子进程需要装入父进程的内存拷贝时分配空间,exec 在需要装入可执行文件时分配空间。一个进程在需要额外内存时可以通过调用 sbrk(n) 来增加 n 字节的数据内存。 sbrk 返回新的内存的地址。
进程创建(细节)
- 将代码和静态数据(初始化变量)加载到内存,再加载到进程的地址空间。(操作系统读取硬盘程序字节,并将其读入到内存中)
- 为程序运行期栈(run-time stack)分配内存,在C语言中我们使用栈来存放局部变量、函数参数和返回地址。操作系统可以使用参数来初始化栈,例如在linux中我们将argc、argv参数填入main中
- 为程序的堆(heap)分配内存,如C语言中使用malloc与free,申请与释放的内存为堆内存。注:堆内存远大于栈内存,因此一些大型数据结构需要使用堆来申请内存。
- 执行一些初始化任务,如一些IO操作。在unix中,每个进程默认情况都会打开3个文件描述符(file descriptor,一个整数句柄),用于标准输入输出和错误。

进程的数据结构(xv6)
1 | // Saved registers for kernel context switches. |
I/O 与 文件描述符
简介:
- I/O: 输入(input)与输出(output),C语言的头文件
<stdio.h>,代表的就是标准输入与输出 - 文件描述符: file descriptor,用一个整数来表示内核管理的对象,进程可以通过该描述符进行读或写,文件描述符接口将这些文件、管道、设备抽象为字节流
获得文件描述符(fd),可以通过打开文件、目录、或设备、创建一个管道(Pipe)、通过复制(duplicate)已经存在的文件描述符
- 进程表: 在xv6中每个进程都会有一个进程表,而文件描述符就是作为其中的一个索引。因此每个进程的私有空间内的文件描述符都是以0开始。
在xv6中,通常情况下,进程会默认定义了3个文件描述符。
- 标准输入:0,将fd=0文件的内容进行读取,也就是读取命令行的内容,等同于C语言中的stdin
- 标准输出:1,将内容输出写入到fd=1的文件中,也就是输出内容到命令行,等同于stdout
- 错误信息:2,将错误信息输出到fd=2的文件中,等同于stderr
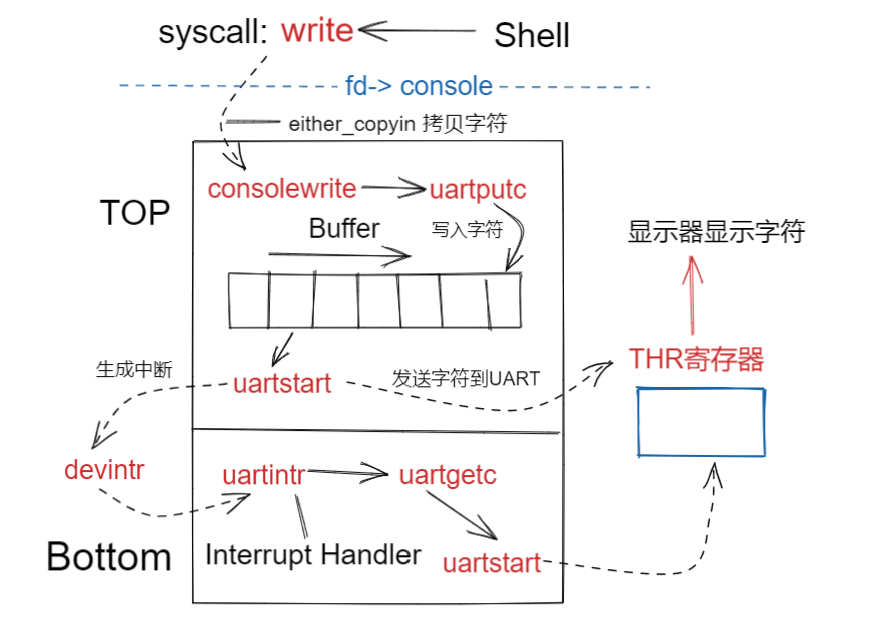
fd = 0,1,2,这三个描述符引用的都是同一个文件console,相当于复制(duplicate)的操作,将三个描述符用于不同的路径。
1 | while((fd = open("console", O_RDWR)) >= 0){ |
I/O系统调用:xv6
| 系统调用 | 描述 |
|---|---|
int open(char *file, int flags) |
打开一个文件,指定读写的标识(flag),返回文件描述符 |
int write(int fd, char *buf, int n) |
将buf的内容写入fd引用的文件,返回值为n |
int read(int fd, char *buf, int n) |
将fd的文件内容读取到buf中,返回读取的数量,如果为0这代表EOF |
int close(int fd) |
释放打开的文件描述符,包括open、pipe、dup所产生的fd,释放后可以复用该fd |
int dup(int fd) |
返回一个新的描述符并引用与fd相同的文件 |
int pipe(int p[]) |
创建管道,将标准输入输出描述符放入p[0]、p[1]中 |
open()接口的第二个参数为标识符(打开文件的方式):
- O_RDONLY:只读
- O_WRONLY:只写
- O_RDWR:读写
- O_CREATE:指定的文件不存在,新建文件
- O_TRUNC:截断,将文件内容清除
应用示例
cat应用:文件位置user/cat.c,我们将open、read、write三个系统接口接口聚合形成了cat这个打印文件内容的程序。
1
2
3
4
5
6
7
8
9
10
11
12
13char buf[512];
int main(int argc,char *agrv[]){
...
for(i = 1; i < argc; i++){
if((fd = open(argv[i], 0)) < 0){
fprintf(2, "cat: cannot open %s\n", argv[i]);
exit(1);
}
cat(fd);
close(fd);
}
...
}
void cat(int fd){
…
while((n = read(fd, buf, sizeof(buf))) > 0) {
if (write(1, buf, n) != n) {
fprintf(2, “cat: write error\n”);
exit(1);
}
}
…
}
1 | 例如我们使用cat打印hello.txt,文件内容为hello world! |
- 首先在main中使用open打开hello.txt,第二个参数0代表只读(kernel / fctrl.c)中定义了O_RDONLY为0x000
- 然后将文件描述符传递给cat函数,根据指定的文件描述符使用read接口读取hello.txt的内容
- 最后再通过write将缓冲区的内容,写入到标准输出中
I/O重定向
I/O重定向: 通常情况我们都是将内容输出到屏幕也就是命令行,通过I/O重定向便可以将内容输出到指定文件内。I/O的重定向 = 将标准输入、输出、错误信息打印,三个文件描述符替换,作为指定文件的描述符
linux下的重定向符号使用
命令 > 文件:将内容输出到指定文件命令 2> 文件,可以将错误信息输出到指定文件命令 >> 文件:以追加的形式输出到指定文件命令 > 文件 2>&1:将标准输出于错误消息输出到指定文件,在后续将会使用到该符号,等同于命令 &> 文件。个人理解:&作为引用相当于duplicate,fd=2作为一个fd=1的副本。1
ls a b > tmp1 2>&1 #b目录不存在,将2(标准错误打印)重定向1(标准输出)
命令 < 文件:将文件内容输入到指定位置,将文件内容作为命令的标准输入命令 < 文件1 > 文件2:将文件1作为命令的标准输入,并将标准输出到文件2
1 | ----打印到屏幕上---- |
实现:
fork()+ 文件描述符
在进程讲解中我们知道了,fork生成的子进程会拷贝父进程的内存,那么父进程的描述符同样会拷贝到子进程。exec()系统调用将会替代调用进程的内存(后续不再执行该进程),但是会保留文件表。
扩展: 在命令行键入
cat,不加上文件名。cat会采用标准输入(fd=0)作为输入流运行程序。键入cat后,cat程序会一直占用标准输入,我们输入一行命令,就会输出一行命令。
由于所有进程默认打开了三个文件描述符0,1,2。因此使用open打开文件的返回值是3。要想单个cat命令能够获取文件内容,我们就需要使用IO重定向。那么我们通过使用fork+exec两个接口来实现重定向,以cat < input.txt为例。
1 |
|
将当前的标准输入(fd = 0)替换为需要读入的文件描述符,也就是关闭完标准输入(fd = 0)后,此时调用open,我们会发现这个文件的描述符为0。这时我们再使用单个cat命令,只会读取我们打开的文件的内容。
为什么我们需要将exec与fork两个接口分开
子进程进行IO重定向,不会影响到主进程的IO设置。根据cat重定向,根据上述程序,若我们只使用一个forkexec,没有更换标准文件描述符的机会,就不可能实现IO重定向的功能。
硬件接口占用问题
虽然父子进程拥有隔离的文件描述符表,但是父子进程共用相同的文件偏移量。也就是当父子进程都使用同一个文件描述符时,我们无法控制其运行的顺序。例如:父子进程同时使用了标准输出的描述符,若没有wait,会出现world\n hello的输出
1 | if(fork() == 0) { |
在上述程序中我们使用了wait(0),让父进程去等待子进程退出,从而控制了执行顺序。
dup接口使用
上述程序使用了dup接口进行改写,复制的fd引用了标准输出(fd=1)
1 | fd = dup(1); |
细节
xv6中的IO重定向(user/sh.c)
1 | case REDIR: |
管道(pipe)
简介:
管道: 是一个小的内核缓冲区提供给进程,作为一对文件描述符。一个用于写,一个用于读。给两个程序中创建一个通讯的管道,能够进行数据交换。
作用: 用于不同进程之间的通讯,省去了临时文件的创建于删除。
示例
该程序wc(wordcount),我们将标准输入连接到了管道的读取端
1 | int p[2]; |
在该程序中我们调用了pipe()系统调用,我们创建了新的管道,在p中记录下了文件的读写描述符。父子进程都标准IO引用同一管道
- 子进程中我们close了标准输入(fd=0)的描述符,使用dup复制了管道输入描述符,从而引用了管道的读取(输入)端。简单来说就是将标准输入替换成了管道输入也就是重定向。
- 父进程中我们关闭了标准读取(输入)管道,将文件内容写入标准写入(输出)管道,从而将内容写入pipe缓冲区
管道数据流向图

父进程比子进程慢一点执行的话,缓冲区没有数据,会不会导致子进程读取失败?
缓冲区没有数据,会有以下三种情况:
等待写入(输出)端写入数据,输入端再进行读取(阻塞)
等待引用写入(输出)端的管道描述符被关闭
在执行exec程序前,执行close(p[1]),若注释该语句,我们将不会有输出。
wc 的一个fd仍然引用了管道的写端,那么 wc 将永远看不到文件的关闭(被自己阻塞)。
- 读取为0,就像读取到EOF一样
用途
在xv6中shell实现了管道,如grep fork sh.c | wc -l。创建两个子进程分别执行,将左端grep输出的内容,发送给了右端wc作为参数。
1 | case PIPE: |

如图:
- 创建两个子进程(c1、c2),创建管道连接左端(写入端)和右端(读取端)
- 左端写入端: 子进程1中,运行runcmd,命令如grep fork sh.c,将内容写入buffer
- 读取端: 子进程2中,运行runcmd,如wc -l,读取buffer的数据
- 互相等待其完成,简单来说一写一读
右端可以包含一个或多个命令,如a|b|c,其中a为写入端,b、c都是读取端,b、c都是两个子进程
Pipe的实际作用
下述示例中管道除了没有临时文件产生没有什么用途了
1 | pipe |
但是管道与临时文件相比也有以下优势
- 管道会自动清理自己;如果是文件重定向,shell 在完成后必须小心翼翼地删除/tmp/xyz。
- 第二,管道可以传递任意长的数据流,而文件重定向则需要磁盘上有足够的空闲空间来存储所有数据。
- 管道可以分阶段的并行执行,而文件方式则需要在第二个程序开始之前完成第一个程序。
- 如果你要实现进程间的通信,管道阻塞读写比文件的非阻塞语义更有效率。
文件系统
简介
文件系统
文件系统
操作系统中用于管理磁盘的软件,可以高效的将用户创建的文件通过I/O设备存储到系统的磁盘中,从而实现持久化地存储数据。
文件类型
- 目录:保存了数据文件与其他目录的名称引用,目录本质上也是文件
- 数据文件:连续的字节数组
- 设备文件:所有硬件都有对应的文件,文件系统通过文件去访问特定的设备。什么是设备文件? - 知乎
文件存储路径
目录和文件将会形成一个树状结构(tree)。
/ 称为根(root)目录是所有文件的开始目录,以/ 开始表示的路径称为绝对路径 ,如/a/b/c,代表访问到了c这个文件或者是目录。反之不是以/开始的路径称为的相对路径。

文件结构
Linux 文件系统会为每个文件分配两个数据结构:索引节点(index node) 和目录项(directory entry),它们主要用来记录文件的元信息和目录层次结构。
索引节点(inode)
文件系统会给硬盘内的每个文件分配一个底层数据结构inode,每一个inode的编号对应一个文件,用于保存文件元信息。在linux下我们可以使用stat命令查看inode消息,inode数据结构存在于磁盘中。
inode中的元信息(metadata) 如
- 索引节点ID:对应文件本身
- 文件的字节数
- 文件类型:数据文件、目录、设备文件
- 链接数,即有多少文件名指向这个inode
- 文件内容在磁盘的位置
目录项(directory entry) = dentry
用来记录文件的名字、inode指针以及与其他dentry的层级关联关系。多个dentry关联起来,就会形成目录结构,但它与inode不同的是,目录项是由内核维护的一个数据结构,不存放于磁盘,而是缓存在内存。
由于inode唯一标识一个文件,而dentry记录着文件的名称,所以目录项和索引节点的关系是多对一,也就是说,一个文件可以有多个名称。
硬盘存储数据
磁盘读写的最小单位是扇区,扇区的大小只有 512B 大小,如果每次读写都以这么小为单位,那这读写的效率会非常低。
所以,文件系统把多个扇区组成了一个逻辑块,每次读写的最小单位就是逻辑块(数据块),Linux 中的逻辑块大小为 4KB,也就是一次性读写 8 个扇区,这将大大提高了磁盘的读写的效率。
以上就是索引节点、目录项以及文件数据的关系,下面这个图就很好的展示了它们之间的关系:

inode是存储在硬盘上的数据,那么为了加速文件的访问,通常会把inode加载到内存中
参考:小林coding
文件系统调用:xv6
| 系统调用 | 描述 |
|---|---|
int chdir(char *dir) |
Change the current directory. |
int mkdir(char *dir) |
Create a new directory. |
int mknod(char *file, int, int) |
Create a device file. |
int fstat(int fd, struct stat *st) |
Place info about an open file into *st. |
int stat(char *file, struct stat *st) |
Place info about a named file into *st. |
int link(char *file1, char *file2) |
Create another name (file2) for the file file1. |
int unlink(char *file) |
Remove a file. |
cddir: 切换当前文件目录,同cd命令
mkdir: 创建目录,同linux下的mkdir命令
mknod: 创建一个特殊的文件,对设备文件进行引用,与设备文件相关的是主要和次要设备编号(mknod的两个参数),它们唯一地标识内核设备。
link:创建一个文件名,对相同的inode进行引用作为一个存在的文件
应用示例
chdir与open
1
2
3
4
5
6/*---使用chdir改变当前目录,以相对路径创建文件---*/
chdir("/a");
chdir("b");
open("c", O_RDONLY);
/*---以绝对路径创建文件---*/
open("/a/b/c", O_RDONLY);mkdir与mknod
1
2
3
4
5
6/*在根目录下创建dir文件夹,并以只写的方式创建file文件*/
mkdir("/dir");
fd = open("/dir/file", O_CREATE|O_WRONLY);
close(fd);
/*创建console设备文件*/
mknod("/console", 1, 1);创建设备文件后,内核回将读写的系统调用转移到内核设备,而不是传递给文件系统
link与unlink
链接(link): 每个链接由目录中的条目也就是(dentry)组成,dentry内容包含文件名与引用的inode
如下,创建b的文件进行读写和对a进行读写的效果相同,对a、b文件使用stat命令进行观察,可以观测到a、b有相同的inode号与一样的链接数(nlink) =2。当使用unlink后,我们再观测b文件会返现nlink=0
1 | /*创建一个文件a,创建b文件对a进行链接*/ |
数据结构(xv6)
fstat系统调用检索inode的文件描述符信息,并将其填入stat结构体中如下所示:
1
2
3
struct stat {
int dev; // File system’s disk device
uint ino; // Inode number
short type; // Type of file
short nlink; // Number of links to file
uint64 size; // Size of file in bytes
};
1 | - cd命令改变shell当前的工作目录,如果cd作为普通命令执行,那么我们将会fork一个子进程,而子进程只会改变当前目录,不会该改变父进程目录。以此不需要fork一个进程去修改目录。 |
总结
本章主要是讲解了系统调用的一些接口,并且简单的介绍了一些linux的常识。本节课也有对应的实验,可以让你去实现一些常用linux的工具lab1(其中十分有趣的实验用pipe去实现流水线)。