Mit6.S081:lab mmap
实验:Lab: mmap
实验开始之前需要将git分支切换到fs分支不然有些文件你是没有的
1 | $ git fetch |
Lab: mmap (hard)
简介
本次实验是实现mmap与munmap这两个系统调用,它们可用于在进程之间共享内存,将文件映射到进程地址空间,并作为用户级缺页方案。在本实验中,我们将向xv6添加mmap和munmap,重点关注内存映射文件。如果忘记了缺页是如何实现的可以回顾COW实验。
如果你不知道mmap系统调用的相关作用以及标识的意义,那么可以在linux下使用man命令查看mmap文档:
1 | man 2 mmap |
如果觉得阅读man的英文手册困难的话可以,查看中文版的手册MMAP - Linux手册页-之路教程 (onitroad.com)。觉得麻烦的话可以直接看mmap解析部分
任务:实现
mmap与munmap的基本功能,以至于能够通过mmaptest的测试,多余的功能并不需要我们去实现
1 | mmaptest |
HINS:参照实验文档自行阅读,一定要阅读!!!
mmap解析
mmap系统调用
1 | void *mmap(void *addr, size_t length, int prot, int flags, |
mmap可以通过多种方式调用,但本实验只需要其与内存映射文件相关的功能的子集。依次介绍以下每个参数的意思。mmap返回该地址,如果失败,则返回0xffffffffffffffffffff,也就是-1。以下是每个参数的涵义:
addr:如果addr始终为零,这意味着内核应该决定映射文件的虚拟地址。length:要映射的字节数;它可能与文件的长度不同。prot:内存是否应该映射为可读、可写和/或可执行的,在fcntl.h中有所定义。flags:在实验中有两个参数MAP_SHARED与MAP_PRIVATE。fd:文件描述符offset:文件中要映射的起点。
接着详细讲解以下flags参数的两个宏:
MAP_PRIVATE,对映射区域的修改只对当前进程可见,不会影响磁盘上的原始文件,也就是释放内存后,不会将修改的数据写回磁盘文件中。如果要将自己在内存上对文件的修改写入文件,就需要在取消映射前,显式的调用write将数据写回。
MAP_SHARED代表共享同一段物理内存,并且对内存区域修改后,munmap释放内存后,会写回磁盘文件中。可以实现多进程之间的数据共享和通信。
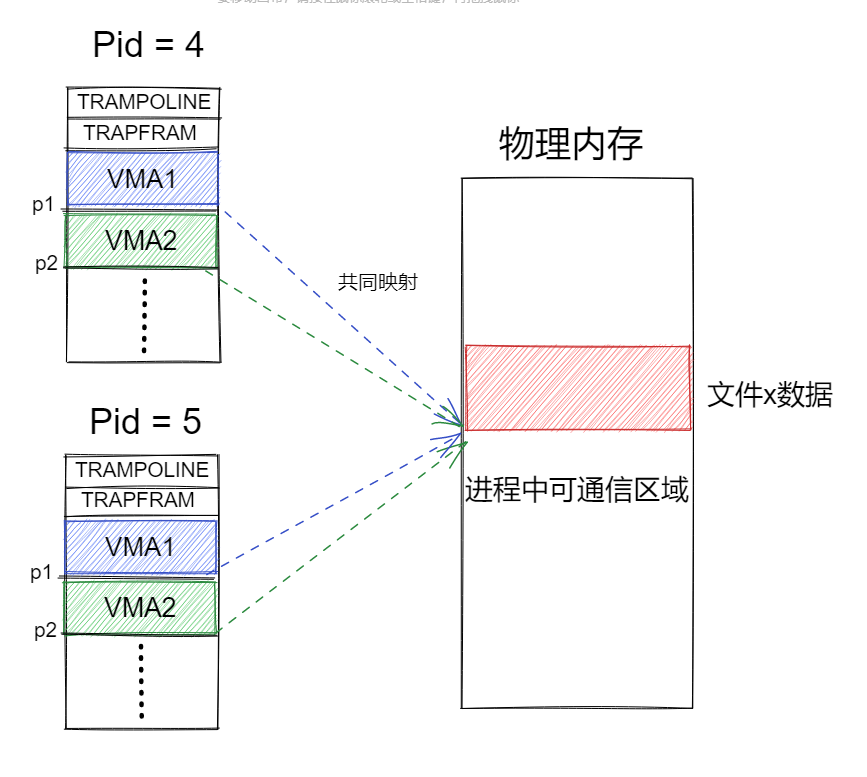
如下图所示,分别创建了两个进程,pid=5是pid=4的子进程。在pid=4中调用了两次相同参数的MAP_SHARED的mmap系统调用,返回的用户内存地址分别为p1与p2,可以发现这两个VMA(virtual memory area)是用户内存区域,不同的两个区域映射在了同一个物理内存上。那么使用fork创建子进程,也会映射在与父进程一样的物理内存区域。
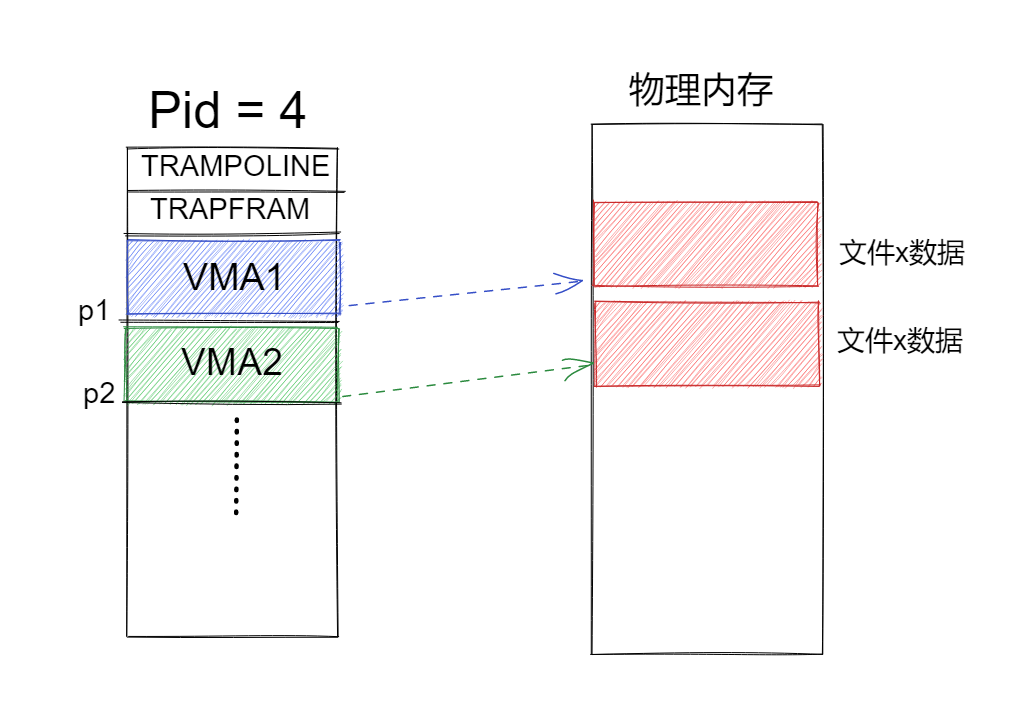
但是实验文档中提醒到,It’s OK if processes that map the same MAP_SHARED file do not share physical pages,也就是在测试程序中并不要求我们共享物理内存。那么我们在实验中实验的内存映射就如下图所示。包括使用fork创建后,我们也不需要共享物理页。(共享物理页在challenge中会要求实现)
munmap系统调用
1 | int munmap(void *addr, size_t length); |
munmap(addr,length)应删除指定地址范围中的mmap映射。如果进程修改了内存并将其映射为MAP_SHARED,则应首先将修改写入文件。
munmap调用可能只覆盖mmap-ed区域的一部分,但您可以假设它将在开始或结束时取消映射,或取消整个区域。但是不能只取消中间的一部分(挖一个洞),如下图所示,这样会导致内存释放(exit函数)的困难,有可能造成内存泄漏。所以通常是从映射的开头,开始取消映射到指定位置;或者是从指定位置,取消到映射的结束位置,这种情况也就需要代码控制。
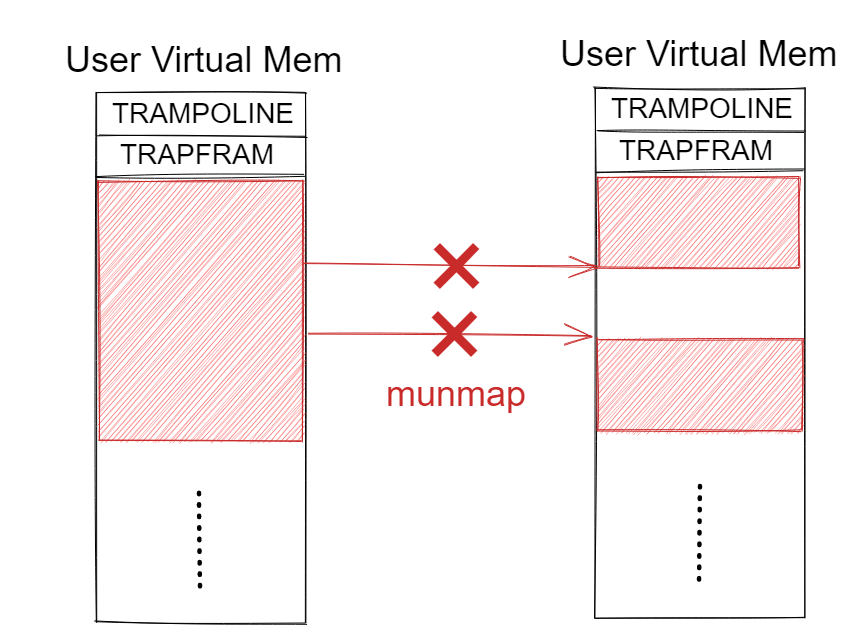
mmap内存映射机制
对于用户进程空间,我们该在哪里开始分配虚拟页?目前有两种方案:
- 从proc结构体的sz字段开始分配,XV6:陷阱 - 知乎 (zhihu.com)的lazy alloation中又所解释,也就是从堆空间往上开始分配。但是这种实现方式会有缺陷,sz字段是与堆空间分配有关的字段,会导致内存分配出现冲突。
- 从顶部往下分配,也就是在
TRAPFRAM页往下分配,用户进程空间是很大的空间(2^64^字节),所以从顶部往下开始分配也不会造成什么冲突。
在本次实验中,使用的方案也是从顶部往下开始分配。
VMA结构
再来讨论一下VMA结构,在实验文档中提到lecture15有所提及VMA,但是我并没有看到。于是我去搜索了linux下的VMA结构,于是定义了HINS中所提到的VMA结构。
如下面代码所示,实际上还是比较简单的,就是在proc结构体中定义一个VMA数组用于mmap,这样的好处是,在调用munmap与触发缺页时,我们都能够找到mmap的相关信息。
1 | ----proc.c |
实现:mmap
添加系统调用接口
老生常谈的在实验前添加系统调用接口。
1 | ----syscall.c |
初始化VMA字段
在分配进程时需要初始化VMA的一些字段,特别是vaild与mapped字段。
1 | static struct proc* |
mmap函数
接着实现mmap系统调用,主要流程如下:
- 使用arg相关函数获得系统调用的6个参数;
- 在建立映射前,处理一些参数错误的状态;
- 在实验中我们只处理addr参数为0的映射,也就是内核来分配用户虚拟内存。需要在进程结构体中获得mmap字段(VMA数组),从中找到一个空的VMA结构用于记录mmap的信息。
- 使用
find_freespace函数查找空闲的虚拟内存地址值 - 初始化VMA结构,并且将VMA结构中的
struct file*的ref字段增加(使用filedup函数),防止文件提前释放。初始化时要注意perm字段的标识是perm<<1 | PTE_U,添加PTE_U是让用户进程能够访问,而perm<<1是PTE的权限位与mmap权限位之间的逻辑关系,就是往左移一位即可。 - 返回VMA的
addr字段的值,这个值就是我们建立映射的虚拟内存的底部值,addr + len字段就是虚拟内存整个映射区域。
1 | ----sysfile.c |
find_freespace函数,用于查找空闲的符合条件的虚拟地址空间区域,这里我的实现是比较简单的。主要是使用了线性查找,由于VMA数组的addr字段是没有经过排序的,当出现VMA数组中保存的内存区域范围不匹配,更换地址范围,直到遍历完整个VMA数组。
其实这样的实现仍会有问题,就是VMA地址字段没有排序的问题,这样会导致地址是乱序的导致范围覆盖,由于mmap_test的测试简单也就没啥问题,如果严谨的话还是排序一下。
如下所示我们虚拟空间的范围是从TRAPFRAME页底部开始作为top的,bottom则是TRAPFRAM-len,通过下面循环便可以实现虚拟空闲地址分配。
1 | uint64 |
实现:mmap缺页handler
通过mmap返回一个虚拟地址后,如果在用户空间使用这个地址就会出现这样的问题,通过scause寄存器可以直到是一个加载页错误(load page fault)。
1 | usertrap(): unexpected scause 0x000000000000000d pid=3 |
按照COW实验的做法,我们就需要修改usertrap函数,在其中添加scause=13的判断,如下所示处理mmap缺页,首先是通过stval的地址(缺页异常的虚拟地址值)找到对应的VMA,并调用mmap_fault函数处理mmap缺页。
1 | ----def.h |
mmap_fault函数的实现并不是很难,主要又几个容易造成困惑的地方:
- 使用readi读取数据时,以
m->f->off为偏移,开始读取文件数据,这时候的问题时,在使用writei写入数据时会修改m->f->off的值,导致文件指针一直处于尾部,导致我们读取不到数据,所以应该采用应该临时的off从m->off开始读取文件数据。 - 使用
mappages的时候不能够一下将所有物理页进行映射,原因就是使用kalloc分配物理页可能并不是连续的,在并发的时候会导致不连续的问题,所有需要采取kalloc分配一个物理页就映射一个页。
mmap_fault的实现如下所示,并且需要标记这个VMA的mapped字段,是否触发缺页,这样就可以方便我们释放物理页。
1 | ----trap.c |
实现:munmap
munmap的实现如下所示,释放过程主要分为两个部分:刚好能够释放完或释放一部分,但是不能在用户映射区域”挖一个洞”。
通过munmap的addr参数,找到指定的VMA结构,通过判断参数len与VMA的len确定是否能够完全释放。
- 能够完全释放,这就比较简单,直接使用
uvmunmap函数将所有页面释放,并清除物理页,将struct file*字段的ref引用数减一,并清空VMA结构体。 - 不能够完全释放,判断
addr是否从VMA映射的起始位置开始释放。如果addr = m->addr,就需要对应的修改len与addr字段;反之,将addr以后的映射区域全部取消。
如果VMA的flags标记为MAP_SHARED,那么在释放前就需要调用writei将物理内存页的修改值写回磁盘文件。
1 | uint64 |
实现:fork与exit
根据HINS提示,我们需要在exit中释放未释放的mmap的映射区域,这时候mapped字段就会起到作用了,只有在触发缺页分配了物理空间后,exit才会将其mmap区域释放。
1 | ----proc.c |
再根据提示,我们对fork进行修改,只需要增加父进程的VMA结构的文件的引用数,并将其拷贝到子进程就可以了,此时再次运行mmap_test,我们的fork_test就可以通过了。
1 | ----proc.c |
总结
完成以上的修改便能够通过mmaptest的测试了,实现结果如下所示。本次实验总体来说并不是很难,但是很全面,包括了内存分配、页表映射、陷阱、缺页、文件读写等等内容。在做这个实验之前再复习一下cow实验,解决起来是没太大问题的。
这个实验本身只是一个综合性的实验,对于mmap大部分细节都没有设计到,如果想要更加的深入实现的话可以尝试解决challenges部分。
挑战
- If two processes have the same file mmap-ed (as in
fork_test), share their physical pages. You will need reference counts on physical pages. - Your solution probably allocates a new physical page for each page read from the mmap-ed file, even though the data is also in kernel memory in the buffer cache. Modify your implementation to use that physical memory, instead of allocating a new page. This requires that file blocks be the same size as pages (set
BSIZEto 4096). You will need to pin mmap-ed blocks into the buffer cache. You will need worry about reference counts. - Remove redundancy between your implementation for lazy allocation and your implementation of mmap-ed files. (Hint: create a VMA for the lazy allocation area.)
- Modify
execto use a VMA for different sections of the binary so that you get on-demand-paged executables. This will make starting programs faster, becauseexecwill not have to read any data from the file system. - Implement page-out and page-in: have the kernel move some parts of processes to disk when physical memory is low. Then, page in the paged-out memory when the process references it.