Mit6.S081:lab net
实验开始之前需要将git分支切换到net分支不然有些文件你是没有的
1 | $ git fetch |
写在前面:本节内容分为实验部分与源码部分,内容可能会有多。如果想要多了解一下源码的读者可以观察源码分析部分。
networking(hard)
简介
qemu模拟设备硬件
本次实验是通过使用qemu在risc-v主板上模拟一个网卡设备称为E1000。这个网卡设备可以连接到真实的局域网中(LAN)。但是在实验中,局域网与网卡设备都是通过qemu模拟出来的。xv6(客户端)的IP地址是10.0.2.15,连接到IP地址为10.0.2.2的局域网上。当xv6使用E1000向10.0.2.2发送数据包时,qemu会将包发送给局域网中目的主机(服务端)中。
要了解e1000网卡的相关内容,可以根据实验中给出的硬件手册的相应章节进行阅读。
网络协议栈
在该实验中提供了较为简单的网络协议栈的代码实现,在后续的源码分析中会又所介绍。陈列一下相关的文件:
sysnet.c:定义了套接字结构,实现了操作套接字链表的方法net.c/net.h:定义了mbuf(packet buffer management)结构体与网络协议栈,并实现了网络包的发送与接受的相应操作方法。e1000.c/e1000.h:定义了e1000网卡的寄存器与e1000的DMA缓冲,实现了网卡驱动对网络包的发送与接受的方法。
DMA:Direct Memory Access
DMA是一种计算机数据传输技术,能够在不干扰CPU的情况下,将数据从存储器(通常是RAM)传输到另一个设备的内存(例如硬盘驱动器或网络适配器)。那么在该实验中时如何实现DMA的呢?
- E1000接受链路层传输过来的数据,硬件内部有building blocks,解析后放入内部缓冲队列,然后以DMA的方式与CPU通信。
网卡内部的缓冲队列,发送和接受都有,分别是TX和RX。DMA机制作用如下:在接收时,DMA引擎将队列中的数据拷贝到内存(RAM),然后中断通知CPU,而不是显式让CPU负责这一块的工作。
在DMA机制前主流是PIO的方式,分为port-mapped IO && memory-mapped IO,都是通过CPU指令对设备寄存器进行读写。在CPU和外部设备速度差异变得非常大时,这样效率就变得很低。
DMA机制是靠网卡设备的DMA Engine实现的,操作系统只起到配合的作用,例如在内存中划分一块DMA缓冲区用于读写。
上文引用自《MIT6.S081》 Lab net - 知乎 (zhihu.com)
在实验中就是将RX与TX这两个缓冲队列的地址字段链接到内存:
- 发送:将要发送的包(mbuf)的内存地址值,填写到TX的addr字段,DMA会将该包的运输到e1000网卡进行发送。
- 接收:当e1000接收到包的时候,DMA会将包运输到内存,RX的addr字段会记录包的内存地址值。注意:在
e1000_init时,xv6已经分配了缓冲包的内存区域并与RX链接起来了。
以上便是DMA的机制内容。
实验要求
完成两个函数e1000_transmit()和e1000_recv(),之后e1000便可以接受和发送网络包了,使用make grade命令进行测试。
HINS:
跟着实验文档中的HINS部分完成对应的流程,一步步的编写代码差不多就可以完成实验,而且本次实验不需要使用gdb来调试。
在运行测试点时,需要先在另一个终端中运行make server。
特别的是,在e1000_trasmit()中要使用mbuf的指针,发送完包后就需要清空包的数据了。在e1000_recv()中需要使用循环结构,一次性读取所有的包。这样可以提高速率,不然会产生多个中断,驱动程序也会出现相应的问题,也就是又遗留的包未被处理。
实现:
发送网络包:e1000_trasmit
发送包的环节主要使用了E1000_TDT(记录TX ring的尾索引)、E1000_TDBAL(记录TX ring的基址)这两个寄存器。
首先,在TX ring初始化时,将TDH(head) = TDT(tail) = 0。xv6要发送一个包就要使TDT+1,e1000就需要将TDH+1就可以发送包了。那么对于DMA引擎的创建的缓冲区来说,xv6是生产者(producer)进行TDT++,e1000是消费者(consumer)进行TDH++。
通过HINS内容一步步实现代码即可:
- 加锁,防止多个CPU竞争资源;
- 读取TDT寄存器获得下一个TX ring的索引,判断status字段的
E1000_TXD_STAT_DD位是否可以发送下一个包,不可以则退出函数; - 可以发送下一个包的话,需要清除该缓冲区的数据清空;
- 将要发送的包的数据填入TX ring;
- 使用指针记录当前包的缓冲包的内存地址值,方便步骤3删除包数据;
- 更新TDT寄存器,更新之后便能e1000便会自动发送网络包。
1 | int |
编写完代码后,在一个终端T1中运行make server,就会开启python所写的一个简单的服务器。然后在另一个终端T2运行make qemu,开启xv6后运行nettests命令,这时候在T1就会显示a message from xv6的消息,说明xv6发送包成功。
接收网络包:e1000_recv
接收包的环节主要使用了E1000_RDT(记录RX ring的尾索引)、E1000_RDBAL(记录RX ring的基址)这两个寄存器。
首先,在RX ring初始化时,将RDH(head) = 0,RDT(tail) = RX_RING_SIZE-1。接收一个包后,e1000将当前RDH作为这个包的索引并且使RDH+1,那么xv6要取出这个包就需要将RDT+1,当RDH = RDT时说明队列已满,而且这个节点是无法使用的,所以这个队列实际上只能接收15个包。
- 加锁,防止并发操作DMA的缓冲区;
- 得到RT ring的尾索引,并将其+1后模
RX_RING_SIZE的值保存为idx; - 通过循环判断,指定索引的RX ring队列的节点的status字段的
E1000_RXD_STAT_DD位是否标记。如果标记说明该节点是可读的,则可以进入循环读取数据; - 新分配一个mbuf,拷贝DMA缓冲区的内容,也就是拷贝RX ring的addr地址字段指向的内存,实际上不使用深拷贝也没啥问题,但是在
net_rx函数内会释放缓冲区的内存,可能会造成问题; - 在调用
net_rx前释放锁,避免死锁。net_rx会解析接收网络的包并将数据填入套接字节点的mbufq队列中; - 更新RDT寄存器,说明xv6已经读取完毕。
1 | static void |
中断执行流程:接受网络包
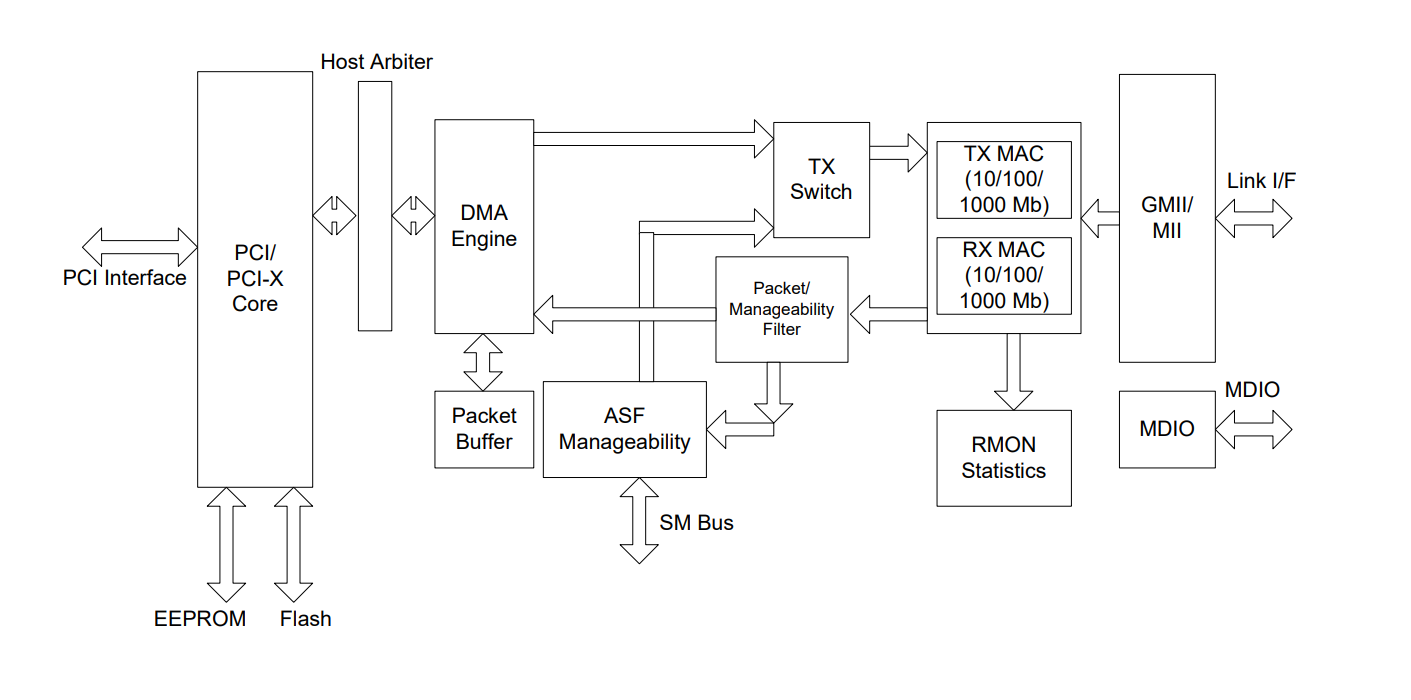
在chapter5中,以top与bottom两个部分分析了驱动的组成,由于发送网络包没有中断的产生(因为DMA存在),所有我们以接收包的流程讲解一下驱动组成。如下图所示
TOP部分
- 在nettest.c代码中使用
connet系统调用获取套接字描述符后,调用了read系统调用,等待从套接字链表中读取数据。 - 进入内核,通过判断文件描述符类型,调用
sockread,因为该sock节点的mbufq队列为空,所以调用sleep函数休眠该进程(shell)。 - 该进程被唤醒后,执行mbufq_pophead()函数从sock节点中读取包的数据。并通过copyout函数将数据内容写回到用户空间。
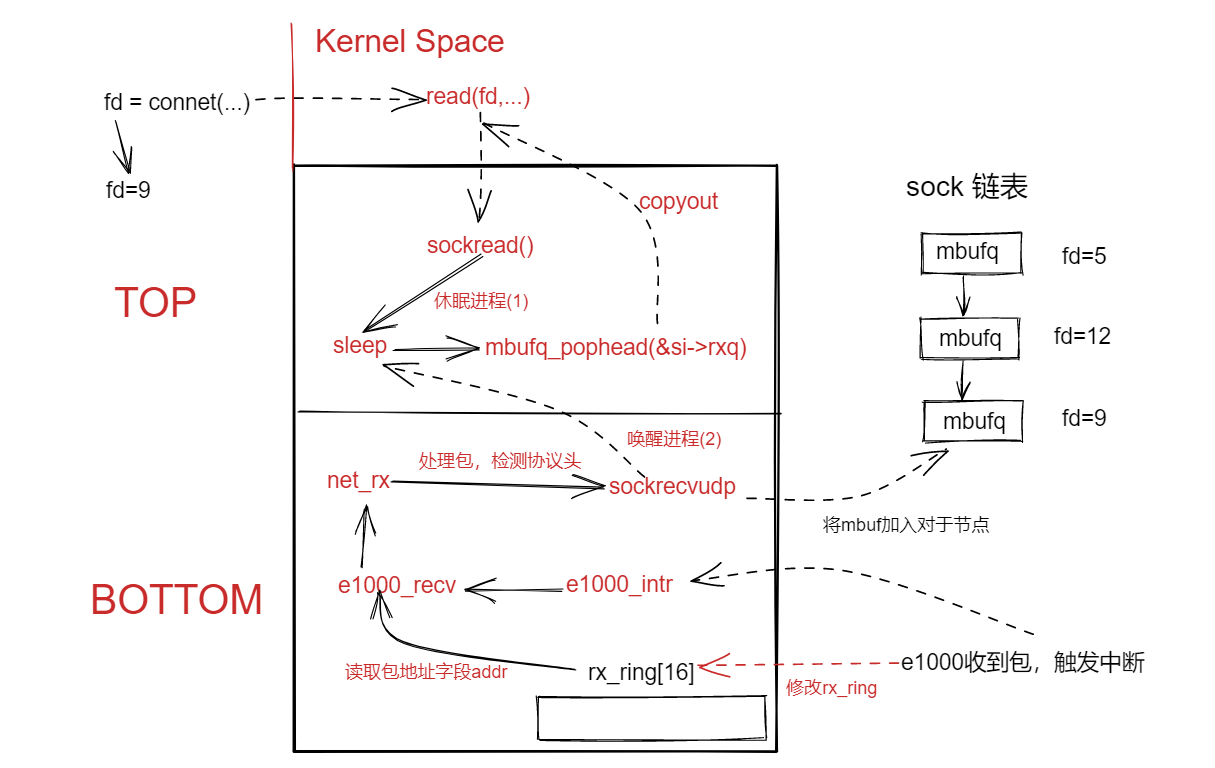
BOTTOM部分
- 当E1000网卡接收到网络包后,产生中断调用interrupt handler(
e1000_intr),其调用了e1000_recv函数. - 在
e1000_recv函数中,从DMA引擎的mbuf(e1000_init中初始化该部分内存)中读取到对应网络包。 - 通过
net_rx、sockrecvudp函数,解析网络包,并将网络包的数据添加到sock节点的mbufq队列的尾部。 - 唤醒TOP部分的休眠进程。
通过TOP与BOTTOM两个部分便可以将驱动代码解耦开来了。
总结
本次实验原则上想通过实验是比较简单的(HINS部分都说明白了),但是这次实验的量级十分的大,包含了网络协议栈、网络硬件驱动设计、DMA等等内容,要想理清整个实验的设计源码,对于自己来说挑战还是十分大的。
主要的难点就是DMA的缓冲设计、intel硬件手册的阅读(全英文,内容晦涩难懂)、网络协议设计。
写完本次实验,实际上对网络硬件的代码也没啥深入的了解,还是需要对其余源码有一些了解。要有更好的提升,还是得对实验中网络文件有一个大致的了解,如果学有余力可以看看下述的源码分析。
源码分析
中断设置
以kernel/main.c文件中的函数调用顺序介绍pci与e1000的初始化设置。
memory map I/O
e1000在RISC-V主板上的位置,和左上角的Rj45的Ethernet一样。CPU对其进行读写数据与读取内存(RAM)是一样的使用的是memory map I/O,对指定的地址段对设备的寄存器进行读写,便能实现对硬件设备的控制。
下述虚拟内存代码中,内核映射建立时可以发现新增了两个地址映射PCI-E ECAM总线与e1000的网卡设备,分别映射在0x30000000L与0x40000000L地址上。可以回顾页表章节就会就可以知晓这些地址段是xv6内核地址中预留的地址段。
1 | ----vm.c |
PLIC传递e1000网卡中断
NOTE:plicinit代码中的设置是有误的,for(int irq = 1; irq < 0x35; irq++)在注释中说明了PCIE设备的IRQs的范围在32-35之间,但是源码中是1-0x35显然是有问题的,在修改位32-35后仍然是正确的。
1 | ----plic.c |
每个CPU核调用该函数,让中断能够被S-mode感知并处理。Q:为什么要先加4以及后面赋值0xffffffff,A:加4代表在上述地址的基础上后移4字节也是32位,0xffffffff刚好对于pci总线上的32个设备,一个设备对应一个位。
1 | ----plic.c |
设置pci总线上的e1000设备
pci设置实际上不是很复杂,主要就是识别e1000网卡的设备id,并配置pci中e1000的地址,让pci总线能够传输e1000的数据。之后便调用e1000_init初始化e1000网卡。
1 | ----pci.c |
__sync_synchronize() 是一种同步原语,用于确保在多线程环境中对共享变量的访问是原子的和有序的。它可以用来防止编译器和处理器对指令进行重排,从而保证代码的正确性。这个函数没有参数,它只是一个内存屏障,用于强制处理器刷新所有存储器和缓存,以确保所有先前的存储操作已经完成(在《锁》章节会继续讲解)。
初始化e1000设备
对e1000网卡进行初始化主要是一下步骤,对于一些控制寄存器,要想深入了解可以继续观看intel硬件手册。
- 重置控制寄存器
- 配置传输寄存器:将TX ring队列的每一个节点都设置
E1000_TXD_STAT_DD位,让其可以传输包;将TX ring的地址写入TDBAL寄存器,这一步就是将e1000寄存器编写使用C语言代替,可以方便的使用C语言编写传输包的控制;配置TDLEN、TDH、TDT寄存器,分别代表了e1000设备中TX ring队列长度、头索引、尾索引。 - 配置接收寄存器:创建DMA引擎的内存缓冲区mbuf,将RX ring节点的
addr字段指向内存区域,这样当包到达e1000后便能够传输到内存区域;将RX ring的地址写入RDBAL寄存器,作用与传输部分一样;配置RDLEN、RDH、RDT寄存器,分别代表了e1000设备中RX ring队列长度、头索引、尾索引。 - 配置MAC地址:将e1000的MAC地址写入RA寄存器。
- 设置多播表,在本实验中并未设置。
- 设置传输、接收控制寄存器的相应的位。
- 中断设置,当e1000接收到网络包后,便能够产生中断。
1 | ----e1000.c |
DMA缓冲区
DMA = 通过DMA引擎,网卡可以直接读取的RAM地址,而不需要内核作为中间商去调配数据的转移。那么在xv6中就设计一种缓冲结构体,这个结构体用于存放网络包字节序列。
mbuf结构体
这个结构体十分的简单,mbuf实际上是一个链表。主要介绍的是char *head字段,这个字段永远指向的都是网络包的头部,如下图所示。
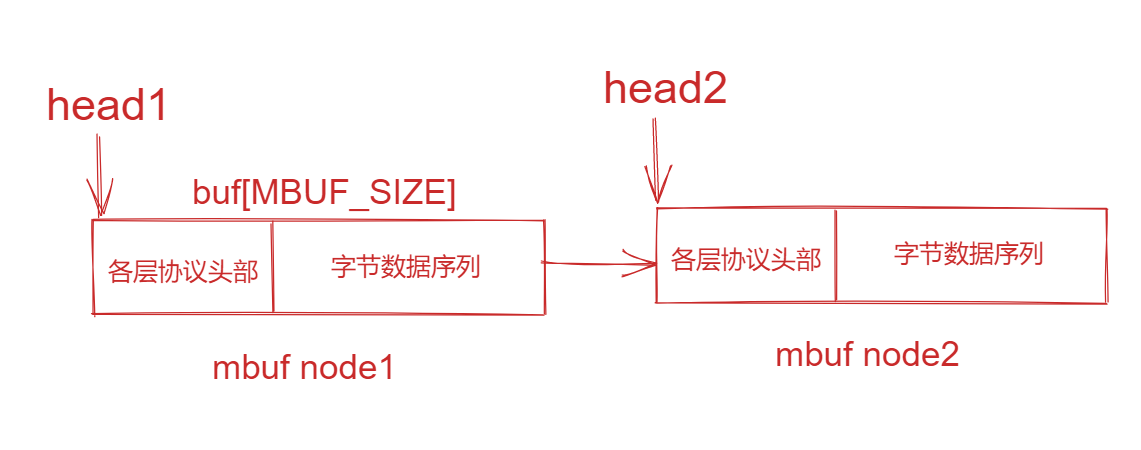
1 | struct mbuf { |
mbuf变式(队列)以及相关函数方法
- 在实验中sock保存便是这个mbufq队列,用于读取mbuf实体的数据,在前文知道了mbuf是一个链表,那么这个mbufq的head、tail则是用于指向mbuf实体的头节点与尾节点。
1 | ----net.h |
- 下述宏定义值得注意的是——
typeof关键字,是GUN C提供的一种特性。类似于C++的decltype关键字,在此处主要是用于推断函数值的返回类型与判断结构类型。
1 | ----net.h |
在发送包阶段会给数据添加各种协议头部,由于每个协议头部的结构体不同,使用该方法便能够将m->head强转为对应结构体类型,之后方便的设置协议的字段了。
- 下述是一些mbuf通用的操作函数
1 | struct mbuf *mbufalloc(unsigned int headroom);//分配一个空的mbuf |
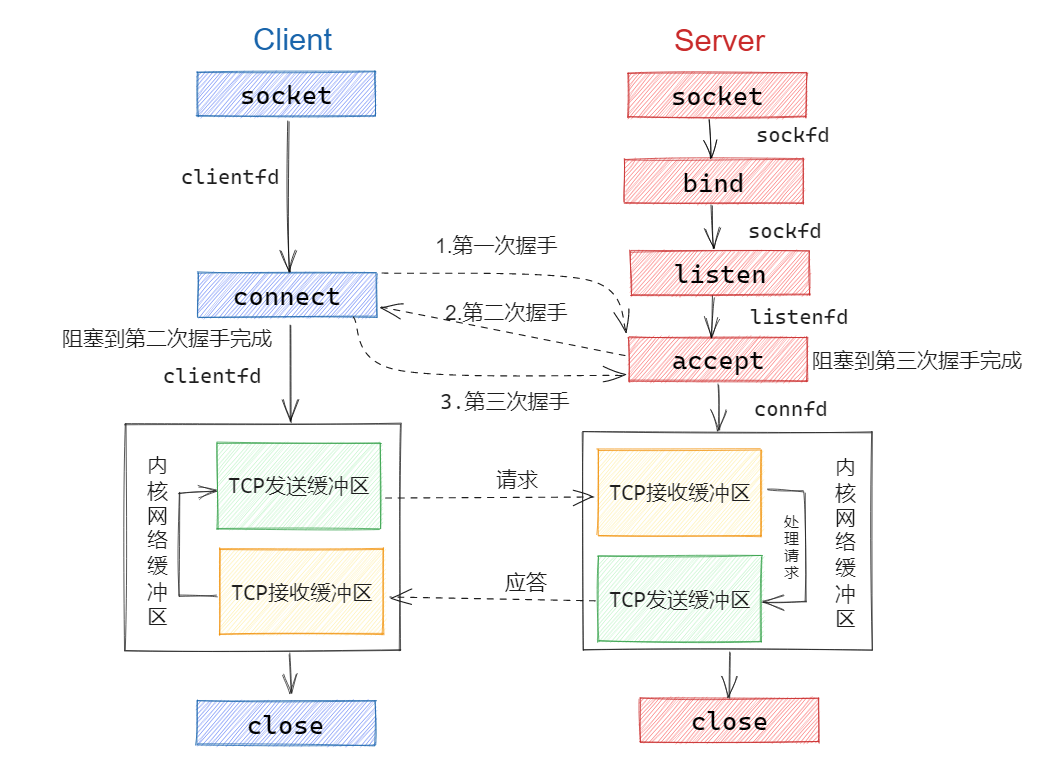
套接字
套接字结构体:链表
套接字是传输层的概念,主要是用于服务端与客户端进程端对端的链接。在net实验中,实现的是sock链表用于记录套接字,套接字中包含mbufq字段包含可以读取的网络包的数据。
每一个套接字对应的是一个文件描述符,通过这个描述符用户空间便能够读取内存中对应sock链表的节点数据。
1 | ----sysnet.c |
套接字分配
在nettest实验中会使用connect系统调用(kernelsysfile.c)用于创建套接字,那么在connect中会调用sockalloc用于创建链表节点。
在新sock节点记录客户端的端口号与服务端的端口号、IP地址,通过判断该节点是否存在于sock链表中,如果存在通过头插的方式将其加入到链表中,反之则清空套接字并退出。
1 | ----sysnet.c |
写入套接字
通过connect获取到套接字描述符fd后,套接字节点与套接字描述符是1对1的关系,使用write(fd,…)后通过识别文件类型便会调用sockwrite,在该函数中主要是创建一个mbuf临时缓冲区并且需要预留网络包的协议头部分。
使用copyin函数将用户空间的要发送的字符串拷贝到mbuf中,并使用net_tx_udp函数将udp的协议头加入到mbuf中,之后便是加入ip、arp、Ethernet协议头到mbuf中。
1 | ----sysnet.c |
读取套接字
与write相似,通过read系统调用sockread函数读取对应的套接字链表。判断套接字的mbuf是否为空,为空则休眠该进程等待mbuf的输入。当该节点的mbuf被写入便会唤醒该节点,那么就可以读取接收的网络包的数据并使用copyout拷贝回用户空间。
1 | ----sysnet.c |
网络协议
网络协议包的加工就如下图所示,从上至下添加每一层的协议头。不同的是,在xv6的ping测试中没有使用应用层的协议,添加的是原生的字符序列。在传输层使用的是udp协议,在链路层添加arp协议头,在物理层添加了以太网Ethernet的协议头。
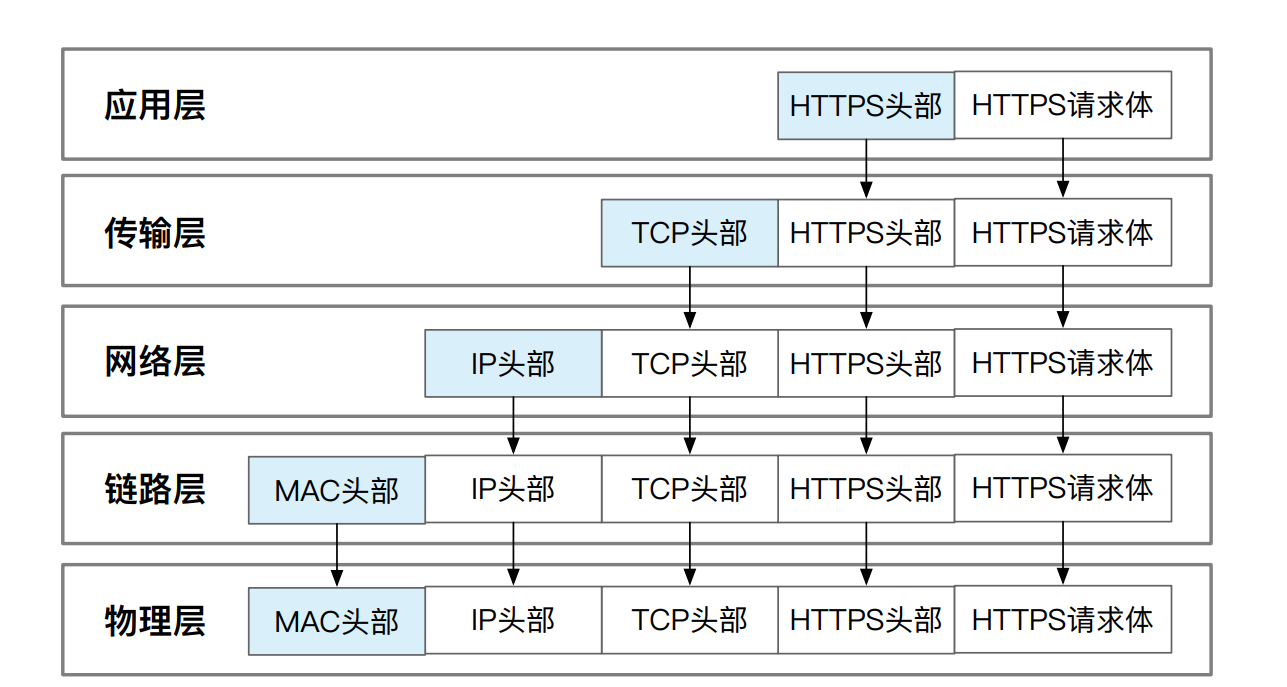
地址信息
在net.h中定义了qemu模拟的xv6主机的ip地址与mac地址。
1 | ----net.h |
物理层:Ethernet
Ethernet结构体
该结构体中简单地定义了Ethernet的协议字段,也就是本机mac地址、目的主机的mac地址,还有协议类型type,在本实验中只有ip与udp类型。
1 | ----net.h |
发送Ethernet包
发送Ethernet包也就是在ip或udp包添加eth头部并发送。发送时候,由于不知道目标主机的mac地址所以目标mac地址被设置为了广播mac地址。之后则是调用e1000_tramit代码是e1000网卡发送eth包。
1 | ----net.h |
接收Ethernet包
解析Eth协议头,通过mbupullhdr函数取出eth协议头,判断Ethernet协议的类型并进一步的取出后一个的协议头部。
1 | ----net.c |
链路层:ARP
ARP虽然实验中有源码,但是在测试中并没有使用arp,因为这个实验是点对点的网络联通测试,所以没有涉及ARP的运用,感兴趣的化可以自行了解。
网络层:IP
IP结构体
在该结构体中定义了一些IP必要的字段,如检验和、包的生存期、本机ip与目的主机的ip等字段,相对来说比较简单,并没有实现IPv6。
1 | ----net.h |
添加ip协议头部与解析头部几乎与Ethernet操作一样,在接收ip包时,net_rx_ip函数会多一些检测如检验和的检测等。
传输层:UDP
结构体
传输层协议有TCP与UDP,在本实验中也涉及不了TCP的设计,UDP的设计也相对比较简单。在挑战中会有TCP设计,感兴趣的话可以尝试一下。
1 | ----net.h |
与IP层相同,添加协议头部与解析协议头部的过程都相似,查看net.c源码是可以读懂的,这里就不赘述了。
应用层:DNS
DNS结构体
看下述结构中有uint8 rd: 1; 这样的对象定义,rd:1是用于声明rd是一个位域变量,位域允许在内存中比较小的空间中表示一个小的整数。这对于网络协议结构非常有用,可以将小的标志位压缩到原本会被浪费的字节内存中。在这个例子中,rd 只需要占用一个bit,而不是完整的字节空间,因此可以节省内存并提高效率。
__attribute__((packed))是GCC编译器的一个扩展属性(attribute),它的作用是取消或减少结构体在编译过程中的对齐优化,使用这个属性主要是让位域不被对齐优化。
1 |
|
对于一些字段的使用可以观察nettests.c的代码会生成dns请求和解析dns请求。
制作DNS请求
传入一个uint8* obuf到函数中,这个地址的数据是DNS请求会在后续的write调用中替代字节序列数据。简短的介绍一下制作DNS请求的步骤:
- 制作DNS头部:将obuf的地址强转为dns结构体对象的基址
- 请求的id值保存到dns对象的字段中,rd赋值为1说明需要递归解析出域名地址,qdcount赋值为1说明只有一个请求。
htons函数方法将本机字节转换为网络字节顺序,Risc-V使用小端序,而网络顺序是大端序。 - 接着是将dns结构体后续的地址强转为需要解析的域名字符串(“pdos.csail.mit.edu.”)的地址,这就是dns要传输的数据部分。
- 制作DNS尾部:将数据部分后续地址强转为dns_question结构体地址。
1 |
|
以上是DNS包的制作,与ping不同的是将字节数据部分替换为DNS头部+数据部分,实际上就是是数据形式变得更加规范。那么这样来说在服务端接收到包之后对其进行对于的解析,可以得到域名的数据。
到此本文就结束了,对于DNS解析部分可以观察对于的代码相对于制作dns请求来说是比较复杂的,但实际上也不难。
挑战
- [ ] In this lab, the networking stack uses interrupts to handle ingress packet processing, but not egress packet processing. A more sophisticated strategy would be to queue egress packets in software and only provide a limited number to the NIC at any one time. You can then rely on TX interrupts to refill the transmit ring. Using this technique, it becomes possible to prioritize different types of egress traffic. (easy)
- [ ] The provided networking code only partially supports ARP. Implement a full ARP cache and wire it in to
net_tx_eth(). (moderate) - [ ] The E1000 supports multiple RX and TX rings. Configure the E1000 to provide a ring pair for each core and modify your networking stack to support multiple rings. Doing so has the potential to increase the throughput that your networking stack can support as well as reduce lock contention. (moderate), but difficult to test/measure
- [ ]
sockrecvudp()uses a singly-linked list to find the destination socket, which is inefficient. Try using a hash table and RCU instead to increase performance. (easy), but a serious implementation would difficult to test/measure - [ ] ICMP can provide notifications of failed networking flows. Detect these notifications and propagate them as errors through the socket system call interface.
- [ ] The E1000 supports several stateless hardware offloads, including checksum calculation, RSC, and GRO. Use one or more of these offloads to increase the throughput of your networking stack. (moderate), but hard to test/measure
- [ ] The networking stack in this lab is susceptible to receive livelock. Using the material in lecture and the reading assignment, devise and implement a solution to fix it. (moderate), but hard to test.
- [ ] Implement a UDP server for xv6. (moderate)
- [ ] Implement a minimal TCP stack and download a web page.