Lab1:MapReduce
Lab1:MAPREDUCE
一、基础框架
paper中的mapreduce概念模型


程序调用
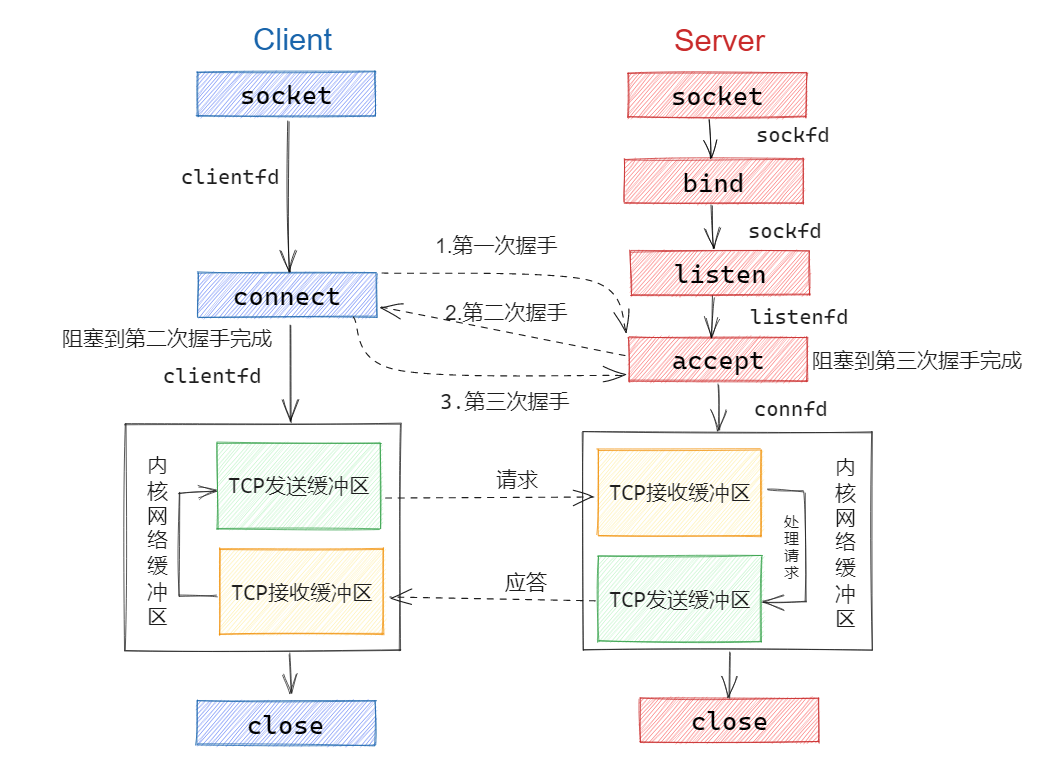
coordinator(master)及worker的调用框架
lab1中的主要是把单进程的map-reduce分开执行并且使用coordinator作为master进行调用
1.工具链(静态库)
将map与reduce的方法放置于wc.go中,然后生成工具链
1 | go build -race -buildmode=plugin ../mrapps/wc.go |
2.挂起coordinator例程
coordinator运行时挂起,打开监听socket,等待worker的请求,并作出响应(返回文件名)
1 | go run -race mrcoordinator.go pg-*.txt |
第二个参数为pg-*.txt,为输入文件
mrcoordinator中调用mr/coordinator.go中的Makecoordinator并传入input文件名与reduce的任务数量
3.打开worker例程(可以打开多个)
mrworker调用mr/worker.go ,mrworker中获取工具链中的mapf-reducef传入worker.go
1 | go run -race mrworker.go wc.so |
worker.go中需要向coordinator发出请求
worker.go 调用map程序输出intermediate文件
将intermediate文件传递给reduce完成工作
二、实验分析

上述为一部分网络上的mapduce的流程
实验心得
刚开始做本次实验,由于没有go语言基础以及做项目的基础,导致做本次实验十分的吃力,一共完成了三版
- 通过上述思路图的实验第一版较为粗糙以及复杂(结构体套结构体的版本,传递一些无效参数),但是没有处理并发问题,导致很多测试点过不了(踩了Struct成员需要首字母大写的坑)
- 实验第二版,实验简化了很多无效使调用关系以及无效参数,调用关系更加明确,但是没有处理并行问题导致出现了任务量达超标的问题。但是莫名其妙的过了Crash测试
- 实验第三版,参考了一点别人的代码,修改了请求任务阶段(使用了Channel),并行问题导致了超标的任务量
并行问题(实验第二版)
并发实现
在Coordianor中将每个Worker申请的服务例程放入goroutine中,多个Worker就是多线程
go http.Serve(l, nil)
在分配Map以及Reduce任务时Coordinate的并行调度问题
用GetMapTask进行示例:
1 | func (c *Coordinator) GetMapTask(args *MapArgs, reply *MapReply) error { |
初始想法
遍历MapTask结构体的数组,去判断哪些任务还未被分配,然后将输入文件和文件ID传给Worker
这个方法偶尔会通过Crash测试,分析应该是任务未完成,State是未被置为true导致,因为Coordinator不断去遍历MapTask数组,就能够发现哪些任务未被完成
Jobcount测试
在该测试中,发现了原本为只需要8个Worker去完成的工作,居然出现了16个!通过查看测试脚本发现了,Jobcount中开启了两个Worker,那么回想并行的状态,一定是两个Worker去读了MapTask数组,又同时去更新了任务,导致了出现了两倍的任务量。
解决并行问题
1 | for { |
1 | //主线程初始化Coordinator |
分析
在实验的第二版中出现了并行问题在于同时这个点,解决方案就是在于同步的问题,当一个线程读取了数据后,另一个线程不能访问,或是及时将另一个线程阻塞或是告知它读取下个任务
使用了Go语言中的Channel的语法,主例程发送一个ID,就会导致阻塞,然后当有Worker调用GetMapTasK将ID读入,才会又下一个ID发送。读写会相互阻塞,这导致在多个Worker中不会去同时读入一个ID,解决了并发问题
Worker与Coordinator之间的关系
Coordinator(RPC的Server机)
- 在Coordinator中需要完成的是定义RPC的方法来完成Worker的请求
- Coordinator结构体中是与Worker通信中需要传递的参数,以及分配任务的一些判断依据,以及多线程中的保护共享数据需的互斥锁(Mutex)
- 由于是多线程并行问题,Coordiantor需要合适去调度任务
Worker(RPC的客户机)
- 在实验中我们可以用一个或则多个(并行)的去向Coordinator申请任务(在多个终端中开启Worker)
go run -race mrworker.go wc.so
- Worker需要去完成Map与Reduce两种任务,Map与Reduce的工具在mrapps中有所定义,所以我们只需定义一些请求任务所需的参数(需要在rpc.go中定义),将这许传回的参数进行相应的任务
- 一个Worker是双线程去完成相应的任务,Worker需要判断任务是否完成,执行怎样的任务,不断的向Coordinator申请任务
- 多个Worker是多线线程并行的去完成相应的任务(任务量测试点)
注意事项:
结构体成员需要以大写字母开始,否则会出现定义为private对象,无法初始化字
三、实验过程
定义对象
rpc中的参数以及回复
1 | //请求Map |
coordinator对象
1 | type Coordinator struct { |
Worker
主要框架
- 一个for死循环,不断的去向主例程申请任务
- 先判断所有任务是否完成也就是判断(向Coordinator询问Reduce任务是否全部完成),完成的话则执行break结束Worker例程,
- 否则进入Map或者Reduce任务,(向Coordinator询问所有Map任务是否完成),Map所有任务完成的话就执行Reduce任务,否则执行Map剩余的Map任务
1 | func Worker(mapf func(string, string) []KeyValue, |
Coordinator
定义Worker例程的调用方法
1 | //MapTask |
Crash开启判断例程(GetMapTask)
1 | select { |
分析
首先知道Worker是一个并行的线程,而这个GetMapTask可以作为Worker线程的一部分,于是Channel可以当作通信的一部分。
设置一个协程,当一个任务Crash掉后,我们要知道是那个任务失败,还要设置一个判断时间,当这个时间过去后判断该状态还未完成,就重新将ID发送,让GetTask能够再次读入并重新执行