Lab 2: Raft — 实验过程记录
写在前面 :Raft是基于共识算法而实现的一个对 fault-tolerant test-and-set service,在MapReduce 、GFS、Fault-Tolerate VM 中都存在一个主要的管理机器(Cooridator 、master、primary) ,集中的去管理、分配任务、复制、同步信息。
参考材料:
Raft Consensus Algorithm ,这时raft的官网,其中有一个有趣的是raft visualization部分,在网页可以可视化的观察的raft执行过程。Raft Q&A :: Jon Gjengset (thesquareplanet.com) ,MIT6.824关于raft的问答raft论文 ,raft算法作者的研究生论文。
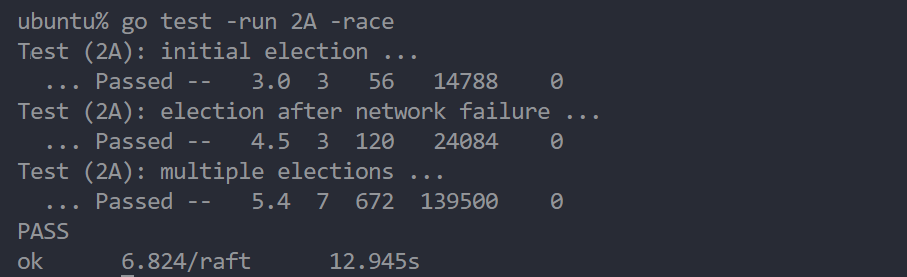
Lab 2A : Leader Election Leader Election(共识算法) 实现implement 按照raft figure 2 的操作将其Raft结构体完善,添加相应的RPC结构体、将State转换封装为rf的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 func (rf *Raft) rf.mu.Lock() rf.State = Follower rf.votedFor = -1 rf.isReceive = false rf.mu.Unlock() } func (rf *Raft) rf.mu.Lock() rf.State = Candidate rf.votedFor = rf.me rf.currentTerm++ rf.isReceive = false rf.mu.Unlock() } func (rf *Raft) rf.mu.Lock() rf.State = Leader rf.isReceive = false rf.mu.Unlock() }
2.ticker()中实现Leader Election(demo) 1 2 3 4 5 6 7 8 9 10 11 for !rf.killed() { rf.isReceive = false time.Sleep(time.Duration((rand.Intn(100 ))+electionInterval) * time.Millisecond) if !rf.isReceive && rf.State != Leader { go rf.StartElection() } else if State == Follower { } }
3.选举(startElection) 1 2 3 4 5 6 7 8 9 10 11 func (rf *Raft) rf.ConvertToCandidate() VoteCounter := 1 for i, p := range rf.peers { if VoteCounter 超过一半{ rf.ConverToLeade() } } }
4.完善RPC处理函数(接收方) S1:sendRPC -> S2
S2: RPChandler 处理sendRPC的请求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 func (rf *Raft) rf.mu.Lock() rf.isReceive = true State := rf.State Term := rf.currentTerm rf.mu.Unlock() if args.Term >= Term { if State != Follower { rf.ConvertToFollower() } rf.mu.Lock() rf.currentTerm = args.Term rf.mu.Unlock() } else { reply.Term = Term reply.Success = false return } } func (rf *Raft) rf.mu.Lock() rf.isReceive = true Term := rf.currentTerm rf.mu.Unlock() if args.Term < Term { reply.Term = Term reply.VoteGranted = false return } else if args.Term > Term { rf.ConvertToFollower() rf.mu.Lock() rf.currentTerm = args.Term rf.mu.Unlock() } rf.mu.Lock() defer rf.mu.Unlock() if rf.votedFor == -1 || rf.votedFor == args.CandidateId { rf.votedFor = args.CandidateId reply.VoteGranted = true } else { reply.VoteGranted = false } }
注意: 在条件判断(if)中去读取变量会导致读取速度慢或是死锁问题,因此应该将共享变量在判断前用临时变量保存
例:将ticker修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 for !rf.killed() { rf.mu.Lock() rf.isReceive = false rf.mu.Unlock() time.Sleep(time.Duration((rand.Intn(100 ))+electionInterval) * time.Millisecond) rf.mu.Lock() State := rf.State rf.mu.Unlock() if !rf.isReceive && State != Leader { rf.StartElection() } else if State == Follower { rf.mu.Lock() rf.votedFor = -1 rf.mu.Unlock() } }
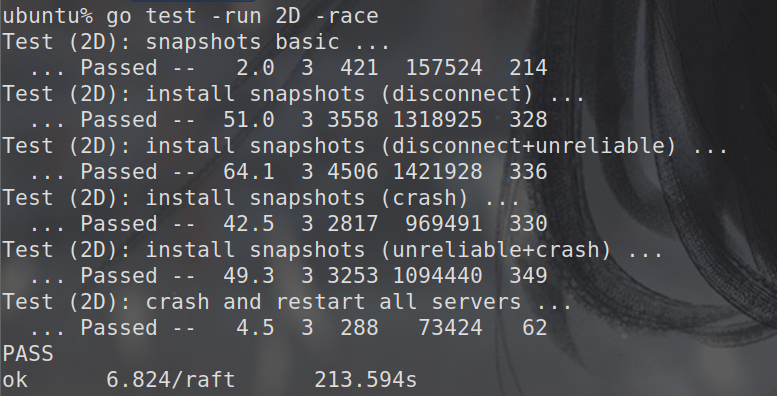
运行结果 测试-race flag
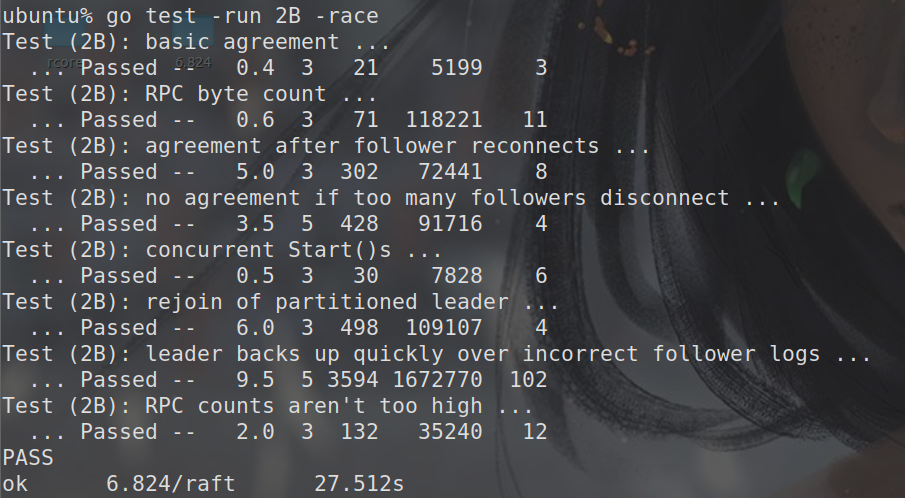
Lab 2B : Log Replicated
根据Raft论文的figure 2完成AE与Start部分的代码
1.AE(接收方Follower的处理log的方式)
更新log
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 func (rf *Raft) rf.mu.Lock() defer rf.mu.Unlock() defer rf.persist() if args.Term >= rf.currentTerm { if rf.State != Follower { rf.ConvertToFollower(args.Term) Debug(dClient, "S%d ConvertTo Follower T:%d(AE)" , rf.me, rf.currentTerm) return } rf.isReceive = true if args.Term > rf.currentTerm { rf.currentTerm, rf.votedFor = args.Term, -1 return } } else { reply.Term, reply.Success, rf.isReceive = rf.currentTerm, false , false return } LastlogEntry := rf.GetLastLogEntry() if args.LeaderCommit > rf.commitIndex && args.Term == LastlogEntry.Term { rf.commitIndex = min(args.LeaderCommit, LastlogEntry.Index) Debug(dCommit, "S%d update CI:%d" , rf.me, rf.commitIndex) rf.applyCond.Broadcast() } if args.Entries == nil { Debug(dTimer, "S%d receive heartbeat from S%d T:%d" , rf.me, args.LeadId, args.Term) return } if !rf.isMatchLog(args.PrevlogIndex, args.PrevlogTerm) { Debug(dLog2, "S%d can't match the PLI:%d" , rf.me, args.PrevlogIndex) reply.Success = false return } reply.Success = true LastAppendEntry := args.Entries[len (args.Entries)-1 ] if LastlogEntry.Term == args.Term && LastlogEntry.Index >= LastAppendEntry.Index { return } lastIncludedIndex := rf.GetFirstLogEntry().Index rf.logs = rf.logs[:args.PrevlogIndex-lastIncludedIndex+1 ] rf.logs = append (rf.logs, args.Entries...) LastlogEntry = rf.GetLastLogEntry() if args.LeaderCommit > rf.commitIndex { rf.commitIndex = min(args.LeaderCommit, LastlogEntry.Index) Debug(dCommit, "S%d update CI:%d" , rf.me, rf.commitIndex) rf.applyCond.Broadcast() } Debug(dPersist, "S%d save T:%d VF:%d LastLog:%v" , rf.me, rf.currentTerm, rf.votedFor, args.Entries[len (args.Entries)-1 ]) }
注意 :该下面条件是由于网络延迟 AE包的到达乱序导致follower的log 被误删(相同prevIndex但是Entries更多的比Entries更少的先到),由于在同一周期的Leader的已经添加的Log不能被删除以及,不同周期内leader不能被删除commit Log,因此有以下判断条件可以将LastlogEntry.Term更换为rf.currentTerm。
1 2 3 4 5 if LastlogEntry.Term == args.Term && LastlogEntry.Index >= LastAppendEntry.Index { return }
updatecommit
更新follower的commitIndex以heartbeat与AppendEntry中携带的信息进行更新即可
2.Start (发送方 Leader)
必要的函数处理
1.log commit后发送ApplyMsg到applyCh
1 2 3 4 5 6 7 8 func (rf *Raft) int , command interface {}) { applyMsg := ApplyMsg{} applyMsg.Command = command applyMsg.CommandIndex = index applyMsg.CommandValid = true rf.ApplySend <- applyMsg }
2.获取N也就是更具matchIndex来判断更新commitIndex的索引
这里先将代码排序后取中位数的方法就可以获取最大的已提交的Index
1 2 3 4 5 6 7 8 9 func GetMid (matchIndex []int ) int { tMatchArr := make ([]int , len (matchIndex)) copy (tMatchArr, matchIndex) sort.Sort(sort.Reverse(sort.IntSlice(tMatchArr))) N := tMatchArr[len (tMatchArr)/2 ] Debug(dCommit, "N :%d,tmatchArr:%v" , N, tMatchArr) return N }
3.大跨步原则快速更新NextIndex
1 2 3 4 5 6 7 func (rf *Raft) int , Args *AppendEntriesArgs) { PrevIndex := Args.PrevlogIndex for PrevIndex > 0 && rf.log[PrevIndex].Term == Args.PrevlogTerm { PrevIndex-- } rf.nextIndex[server] = PrevIndex + 1 }
4.获取最后一个log
1 2 3 4 5 6 func (rf *Raft) LastIndex := len (rf.log) - 1 logEntry := rf.log[LastIndex] return logEntry }
replicate log
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 rf.mu.Lock() if rf.nextIndex[server] < 1 { rf.nextIndex[server] = 1 rf.mu.Unlock() continue } else if rf.State != Leader { rf.mu.Unlock() break } ----------------------------------------------- if LastlogEntry.Index >= rf.nextIndex[server] { Success, ok := rf.CallAE(server, Args) if !ok { break } if !Success { rf.mu.Lock() rf.OptimizeReduce(server, Args) rf.mu.Unlock() continue } }
注意事项 :发送RPC的过程不能加锁
在发送callAE时不能进行加锁操作,因为当follower失联后会导致server收到回复十分的缓慢,这样的话锁资源不能及时释放会导致sendheartbeat等需要锁资源的活动停止行动
更新commitIndex以及应用apply
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 rf.mu.Lock() if Args.PrevlogIndex+len (Args.Entries) > rf.matchIndex[server] { rf.matchIndex[server] = Args.PrevlogIndex + len (Args.Entries) rf.nextIndex[server] = rf.atchIndex[server] + 1 } N := GetMid(rf.matchIndex) cond.Broadcast() if rf.log[N].Term == rf.currentTerm && N > rf.commitIndex { rf.commitIndex = N for i, p := range rf.peers { if rf.peers[rf.me] == p { continue } } for rf.commitIndex > rf.lastApplied { rf.lastApplied++ rf.SendApply(rf.lastApplied, rf.log[rf.lastApplied].Command) } } rf.mu.Unlock()
3.实现Election striction(#5.41)
RV
follower只会给比自己日志更新(up-to-date)的candidate授予票
1 2 3 4 5 6 7 8 9 10 if args.LastlogTerm != LogEntry.Term { reply.VoteGranted = args.LastlogTerm > LogEntry.Term } else { reply.VoteGranted = args.LastlogIndex >= LogEntry.Index } if reply.VoteGranted { rf.votedFor = args.CandidateId } else { Debug(dVote, "S%d Log is more new than S%d reject vote" , rf.me, args.CandidateId) }
相应的在startElection处RPC参数中添加上LastlogTerm参数即可
运行结果:
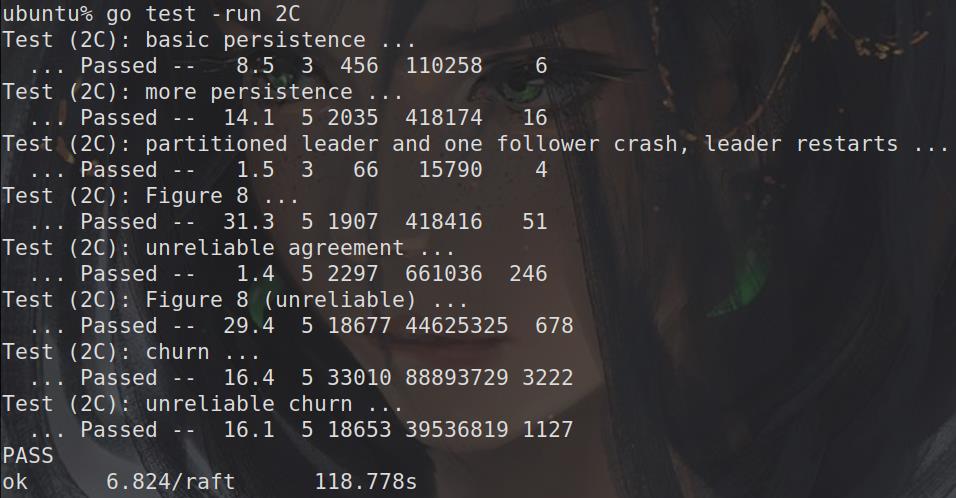
Lab 2C:Persistent State 1.Persist 函数完善 persist():将Persist state写入磁盘,根据figure2 中所述将currentTerm、votedFor、log状态写入磁盘(本次实验实际上是序列化与反序列化),此函数需要在Persist State修改后插入此函数
1 2 3 4 5 6 7 8 9 func (rf *Raft) w := new (bytes.Buffer) e := labgob.NewEncoder(w) e.Encode(rf.currentTerm) e.Encode(rf.votedFor) e.Encode(rf.log) data := w.Bytes() rf.persister.SaveRaftState(data) }
readpersist():在Server Crash后重启调用Make(…),将Crash前保存的状态进行读取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func (rf *Raft) byte ) { if data == nil || len (data) < 1 { return } r := bytes.NewBuffer(data) d := labgob.NewDecoder(r) var currentTerm int var votedFor int var Log []LogEntry if d.Decode(¤tTerm) != nil || d.Decode(&votedFor) != nil || d.Decode(&Log) != nil { log.Fatal("read error" ) } else { rf.currentTerm = currentTerm rf.votedFor = votedFor rf.log = nil rf.log = append (rf.log, Log...) Debug(dPersist, "S%d Read State T:%d VF:%d Log:%v" , rf.me, rf.currentTerm, rf.votedFor, rf.log) } }
2.RPC:失败重传 任何RPC都要保证传送成功,只有当前节点状态发生改变或是传送成功时才停止
RV
1 2 3 4 5 6 7 8 9 10 for !ok { rf.mu.Lock() if rf.State != Candidate { rf.mu.Unlock() return } rf.mu.Unlock() VoteGranted, ok = rf.CallRV(server, Args) time.Sleep(10 * time.Millisecond) }
AE
1.replicate log
1 2 3 4 5 Success, ok := rf.CallAE(server, Args) if !ok { Debug(dDrop, "S%d -> S%d can't replicated log" , rf.me, server) continue }
2.Update CommitIndex
1 2 3 4 5 6 7 8 9 10 for !ok { rf.mu.Lock() if rf.State != Leader { rf.mu.Unlock() break } rf.mu.Unlock() _, ok = rf.CallAE(server, Args) time.Sleep(10 * time.Millisecond) }
3.终止僵尸进程(heartbeat)(使用rf.killed()) Debug:在发送heartbeat时leader crash后重启,该heartbeat进程尚未终止,因此当heartbeat全部都发送失败时则将状态转变为follower
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 func (rf *Raft) heartbeatInterval := 35 var ok bool = true .... for !rf.killed() { _, ok = rf.GetState() if !ok { return } else { ... rf.mu.Unlock() rf.Sendheartbeat(args) time.Sleep(time.Duration(heartbeatInterval) * time.Millisecond) } } }
4.Unreliable:网络中的复杂通信问题
Figure8Unreliable2C的测试点中的fail to reachment
该测试点就是模拟了网络中的复杂的情况,它将包的传输顺序打乱然后随机的增加网络的传输延迟
问题分析
在log中的显示实际上是,在最后的cfg.one(..)中要求在一定时间内将所有的log commitIndex更新到一致
在处理包的实际中存在延迟问题,需要加以优化
Students’ Guide to Raft:不要随意重置election
Make sure you reset your election timer exactly when Figure 2 says you should. Specifically, you should only restart your election timer if a) you get an AppendEntries RPC from the current leader (i.e., if the term in the AppendEntries arguments is outdated, you should not reset your timer); b) you are starting an election; or c) you grant a vote to another peer
a) 过期的RPC包不重置
1 2 3 4 5 6 7 8 if rf.currentTerm < args.Term{ reply.Term = Term reply.Success = false rf.mu.Lock() rf.isReceive = false rf.mu.Unlock() return }
b) 开始election可以重置
1 2 3 4 5 func (rf *Raft) ... rf.isReceive = true ... }
c) RV:给另一个peer投票后才重置
1 2 3 4 5 if reply.VoteGranted { rf.votedFor = args.CandidateId } else { Debug(dVote, "S%d Log is more new than S%d reject vote" , rf.me, args.CandidateId) }
5.实验结果:
性能优化ReplicateLog Batch and PipelineTikv 对于服务请求会多次的调用Start()去添加log,但是若每次添加Log都去触发ReplicateLog的话,那么会导致性能上的浪费。
Batch: 我们可以等待Start()添加log到达一定数量时去唤醒Relicate协程,将一批次的Log进行ReplicateLog
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 const BatchMaxSize = 10 var BatchInterval = 9 var BatchMutex sync.Mutexvar batchNum int = 0 func (rf *Raft) BatchMutex.Lock() batchNum++ if batchNum >= BatchMaxSize { batchNum = 0 BatchMutex.Unlock() rf.replicateTopeers() } else { BatchMutex.Unlock() time.Sleep(time.Duration(BatchInterval) * time.Millisecond) batchNum = 0 rf.replicateTopeers() } }
Pipeline: 如果只是用 batch,Leader 还是需要等待 Follower 返回才能继续后面的流程,我们这里还可以使用 Pipeline 来进行加速。Leader 会维护一个 NextIndex 的变量来表示下一个给 Follower 发送的 log 位置,只负责多发,保证速率,包的顺序由接收方Follower去控制,不用在意Follower的返回。(接收方能够确保包的序列,保存或者丢弃无用的包,例如TCP中的pipeline)
1 2 3 4 5 6 7 8 func (rf *Raft) for i, p := range rf.peers { if rf.peers[rf.me] == p { continue } go rf.replicate(i) } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 func (rf *Raft) int ) { for !rf.killed() { rf.mu.Lock() if rf.State != Leader { rf.mu.Unlock() break } lastlogIndex := rf.GetLastLogEntry().Index if lastlogIndex >= rf.nextIndex[server] { args := rf.GetAppendArgs(server) rf.mu.Unlock() Success, ok := rf.CallAE(server, args) if !ok { time.Sleep(time.Duration((rand.Intn(30 ))+electionInterval) * time.Millisecond) continue } if !Success { rf.mu.Lock() lastIncludedIndex = rf.GetFirstLogEntry().Index if args.PrevlogIndex <= lastIncludedIndex { rf.mu.Unlock() rf.Install(server, lastIncludedIndex) return } rf.OptimizeReduce(server, args) rf.mu.Unlock() continue } rf.handleAEReply(server, args) return } else { rf.mu.Unlock() return } } }
Asynchronous Apply 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 rf.applyCond = sync.NewCond(&rf.mu)go rf.applier() go rf.applier()------------------------------- func (rf *Raft) for !rf.killed() { rf.mu.Lock() for rf.lastApplied >= rf.commitIndex { rf.applyCond.Wait() } commitIndex := rf.commitIndex rf.mu.Unlock() var Command interface {} for commitIndex > rf.lastApplied { rf.lastApplied++ Command = rf.log[rf.lastApplied-rf.LastIncludedIndex].Command rf.SendApply(rf.lastApplied, Command) } Debug(dCommit, "S%d LAI:%d LCI:%d" , rf.me, rf.lastApplied, rf.commitIndex) } }
1 2 3 4 5 6 7 8 9 for i, p := range rf.peers { rf.matchIndex[i], rf.nextIndex[i] = 0 , rf.GetLastLogEntry().Index+1 if p == rf.peers[rf.me] { continue } rf.replicateCond[i] = sync.NewCond(&sync.Mutex{}) go rf.replicator(i) }
1 2 3 4 5 6 7 8 9 10 11 12 func (rf *Raft) int ) { rf.replicateCond[server].L.Lock() defer rf.replicateCond[server].L.Unlock() for !rf.killed() { for rf.nextIndex[server] > rf.GetLastLogEntry().Index { rf.replicateCond[server].Wait() } rf.replicate(server) } }
1 2 3 4 5 6 7 8 9 func (rf *Raft) for i := range rf.peers { if rf.me == i { continue } rf.replicateCond[i].Signal() } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 func (rf *Raft) int ) { rf.mu.Lock() if rf.GetFirstLogEntry().Index > rf.nextIndex[server] { Args := &InstallSnapshotArgs{} rf.mu.Unlock() rf.CallISS(server, Args) } else { rf.mu.Unlock() rf.mu.Lock() if rf.State != Leader { rf.mu.Unlock() return } args := rf.GetAppendArgs(server) rf.mu.Unlock() Success, ok := rf.CallAE(server, args) if !ok { rf.replicateCond[server].Signal() return } if !Success { rf.OptimizeReduce(server, args) rf.replicateCond[server].Signal() return } rf.handleAEReply(server, args) rf.replicateCond[server].Signal() } }
总结:
batch的使用会导致测试时间加长,因为在实验中并没有大量的数据用以测试,而且在有时会用one()来要求所有peer的数据强制统一,这强制共识会花费一定的时间,并且设置了一个batchInterval 的时间间隔,只有batchtime超时后才进行replicate,导致时间加长。而且对于2B的最后一个测试点,batch操作也会导致发送过多的heartbeat导致无法通过。
时间延迟等问题还未太过研究
Lab 2D: Compaction Log
在实验二中并不会去实现快照只是实现日志压缩,快照的相关实现会在Lab3中实现
Snapshot的作用:
raft层裁剪日志 :该服务属于服务层的应用接口(在VM ware 中就有该功能),当客户端或者服务层发现log的size到达一定数量时会导致磁盘空间膨胀 ,因此,我们将使用snapshot对于一定的log进行裁剪删除 。
服务层保存状态机状态 :对于服务层来说,日志到达指定大小后服务端调用Snapshot()会将applied 的日志的状态机的状态(数据库…) 进行快照拍摄,并将改状态之前的日志压缩也即是丢弃,当服务端crash后可以读取改快照时的状态到达快速恢复的作用
Snapshot的接口:
snapshot(): log到达一定数量后进行裁剪和压缩
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 func (rf *Raft) int , snapshot []byte ) { rf.mu.Lock() defer rf.mu.Unlock() lastIncludedIndex := rf.GetFirstLogEntry().Inde if index <= lastIncludedIndex { return } rf.CompactLog(index, snapshot) } func (rf *Raft) int , snapshot []byte ) { lastIncludedIndex := rf.GetFirstLogEntry().Index rf.logs = rf.logs[index-lastIncludedIndex:] rf.logs[0 ].Command = nil rf.snapshotpersist(snapshot) go rf.SendApplySnapshot(index, rf.logs[0 ].Term, snapshot) }
condInstallsnapshot(): 服务层进行协调log与snapshot,主动调用该函数判断是否需要安装快照,服务层发现Applych发送过来的snapshot消息来判断是否还是需要重新调用snapshot()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 func (rf *Raft) int , lastIncludedIndex int , snapshot []byte ) bool { rf.mu.Lock() defer rf.mu.Unlock() if lastIncludedIndex <= rf.commitIndex { return false } if lastIncludedIndex > rf.GetLastLogEntry().Index { rf.logs = nil rf.logs = make ([]LogEntry, 1 ) go rf.SendApplySnapshot(lastIncludedIndex, lastIncludedTerm, snapshot) } else { rf.CompactLog(lastIncludedIndex, snapshot) } rf.logs[0 ].Term, rf.logs[0 ].Index = lastIncludedTerm, lastIncludedIndex rf.lastApplied, rf.commitIndex = lastIncludedIndex, lastIncludedIndex rf.snapshotpersist(snapshot) return true }
saveStateAndSnapshot() :
1 2 3 4 5 6 7 8 9 func (rf *Raft) byte ) { w := new (bytes.Buffer) e := labgob.NewEncoder(w) e.Encode(rf.currentTerm) e.Encode(rf.votedFor) e.Encode(rf.logs) data := w.Bytes() rf.persister.SaveStateAndSnapshot(data, snapshot) }
ReadSnapshot() :服务层恢复后读取snapshot进行恢复
InstallSnapshot RPC
Leader对滞后的follower进行发送snapshot RPC,follower在处理InstallSnapshot时,让follower直接更新到Leader的SM_state,并将其log全部删除(因为leader最小的日志索引都大于了follower),
将其SM_state传输到服务层进行同步,因为follower时滞后的状态通过传送applyCh给服务层进行判断并存储即可
发送时机:
当nextIndex[server] <= firstIndex(LastIncluded)
1 2 3 4 5 if rf.nextIndex[server] <= lastIncludedIndex { rf.mu.Unlock() rf.Install(server, lastIncludedIndex) return }
当发送此次RPC时最开始的index(lastIncludedIndex)都与follower匹配不上
1 2 3 4 5 6 7 8 9 10 11 12 13 if !Success { rf.mu.Lock() lastIncludedIndex = rf.GetFirstLogEntry().Index if args.PrevlogIndex <= lastIncludedIndex { rf.mu.Unlock() rf.Install(server, lastIncludedIndex) return } rf.OptimizeReduce(server, args) rf.mu.Unlock() continue }
发送InstallRPC:SnapshotRPC中的offset与done的参数也不需要完成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 func (rf *Raft) int , lastIncludedIndex int ) { rf.mu.Lock() Debug(dSnap, "S%d -> S%d Send ISS" , rf.me, server) lastIncludedTerm := rf.GetFirstLogEntry().Term snapshot := rf.persister.ReadSnapshot() args := &InstallSnapshotArgs{ Term: rf.currentTerm, LeaderId: rf.me, LastIncludedIndex: lastIncludedIndex, LastIncludedTerm: lastIncludedTerm, Data: snapshot, } rf.mu.Unlock() if rf.CallISS(server, args) { rf.mu.Lock() rf.nextIndex[server] = rf.GetLastLogEntry().Index Debug(dTrace, "S%d -> S%d (ISS)update nextIndex:%d" , rf.me, server, rf.nextIndex[server]) rf.mu.Unlock() } }
RPC处理
若传送过来的LastIncludeIndex <= rf.commitIndex则可以说明follower已经同步snapshot中的状态,不需要用此条消息中的snapshot去更新上层状态机,因此不需要处理这条消息。
既然follower的log已经滞后,那么将其长度进行判断后删除log和旧的snapshot,然后args中的data[]作为snapshot持久化后再通过channel上传到service层。
1 2 3 4 5 6 7 8 9 10 11 12 13 func (rf *Raft) rf.mu.Lock() defer rf.mu.Unlock() ... if args.LastIncludedIndex <= rf.commitIndex { return } Debug(dSnap, "S%d <- S%d InstallSnap LII:%d" , rf.me, args.LeaderId, args.LastIncludedIndex) go rf.SendApplySnapshot(args.LastIncludedIndex, args.LastIncludedTerm, args.Data) }
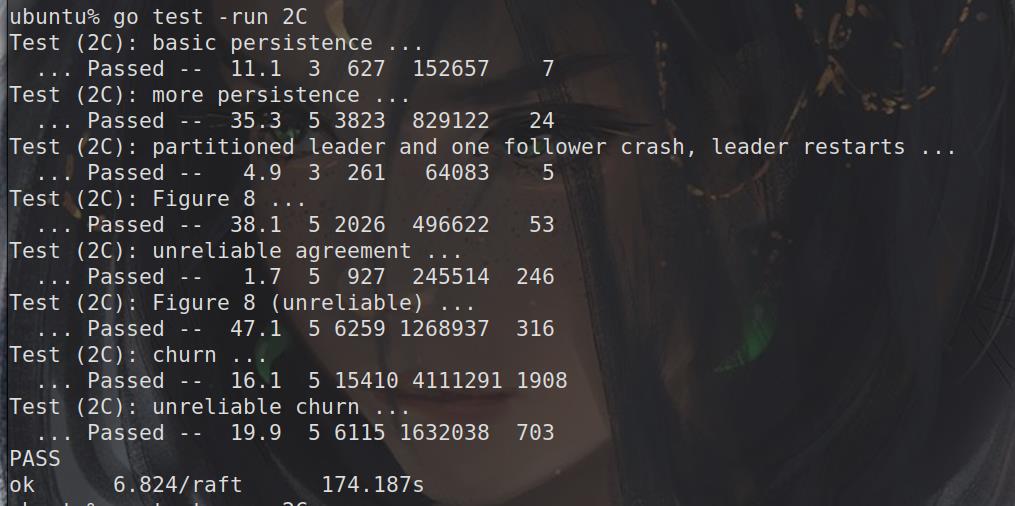
Lab2测试结果 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 ubuntu% go test -run 2 Test (2A): initial election ... ... Passed -- 3.0 3 152 37666 0 Test (2A): election after network failure ... ... Passed -- 5.6 3 363 72800 0 Test (2A): multiple elections ... ... Passed -- 5.5 7 1322 276420 0 Test (2B): basic agreement ... ... Passed -- 0.4 3 23 5697 3 Test (2B): RPC byte count ... ... Passed -- 0.6 3 75 119217 11 Test (2B): agreement after follower reconnects ... ... Passed -- 5.1 3 290 69423 8 Test (2B): no agreement if too many followers disconnect ... ... Passed -- 3.5 5 415 87611 3 Test (2B): concurrent Start()s ... ... Passed -- 0.5 3 21 5239 6 Test (2B): rejoin of partitioned leader ... ... Passed -- 6.1 3 493 107841 4 Test (2B): leader backs up quickly over incorrect follower logs ... ... Passed -- 9.2 5 3107 1524763 102 Test (2B): RPC counts aren't too high ... ... Passed -- 2.0 3 126 31740 12 Test (2C): basic persistence ... ... Passed -- 8.3 3 453 110028 6 Test (2C): more persistence ... ... Passed -- 14.3 5 2031 421054 16 Test (2C): partitioned leader and one follower crash, leader restarts ... ... Passed -- 1.3 3 59 14177 4 Test (2C): Figure 8 ... ... Passed -- 32.8 5 1919 414186 49 Test (2C): unreliable agreement ... ... Passed -- 1.6 5 1547 462287 246 Test (2C): Figure 8 (unreliable) ... ... Passed -- 41.1 5 15167 15643471 441 Test (2C): churn ... ... Passed -- 16.2 5 21731 148707193 2309 Test (2C): unreliable churn ... ... Passed -- 16.1 5 6125 5732595 603 Test (2D): snapshots basic ... ... Passed -- 1.8 3 651 177508 206 Test (2D): install snapshots (disconnect) ... ... Passed -- 47.6 3 3687 1268045 303 Test (2D): install snapshots (disconnect+unreliable) ... ... Passed -- 74.8 3 5734 2004161 359 Test (2D): install snapshots (crash) ... ... Passed -- 37.7 3 2951 1224282 365 Test (2D): install snapshots (unreliable+crash) ... ... Passed -- 66.3 3 4643 1664199 355 Test (2D): crash and restart all servers ... ... Passed -- 3.5 3 386 98139 57 PASS ok 6.824/raft 404.893s